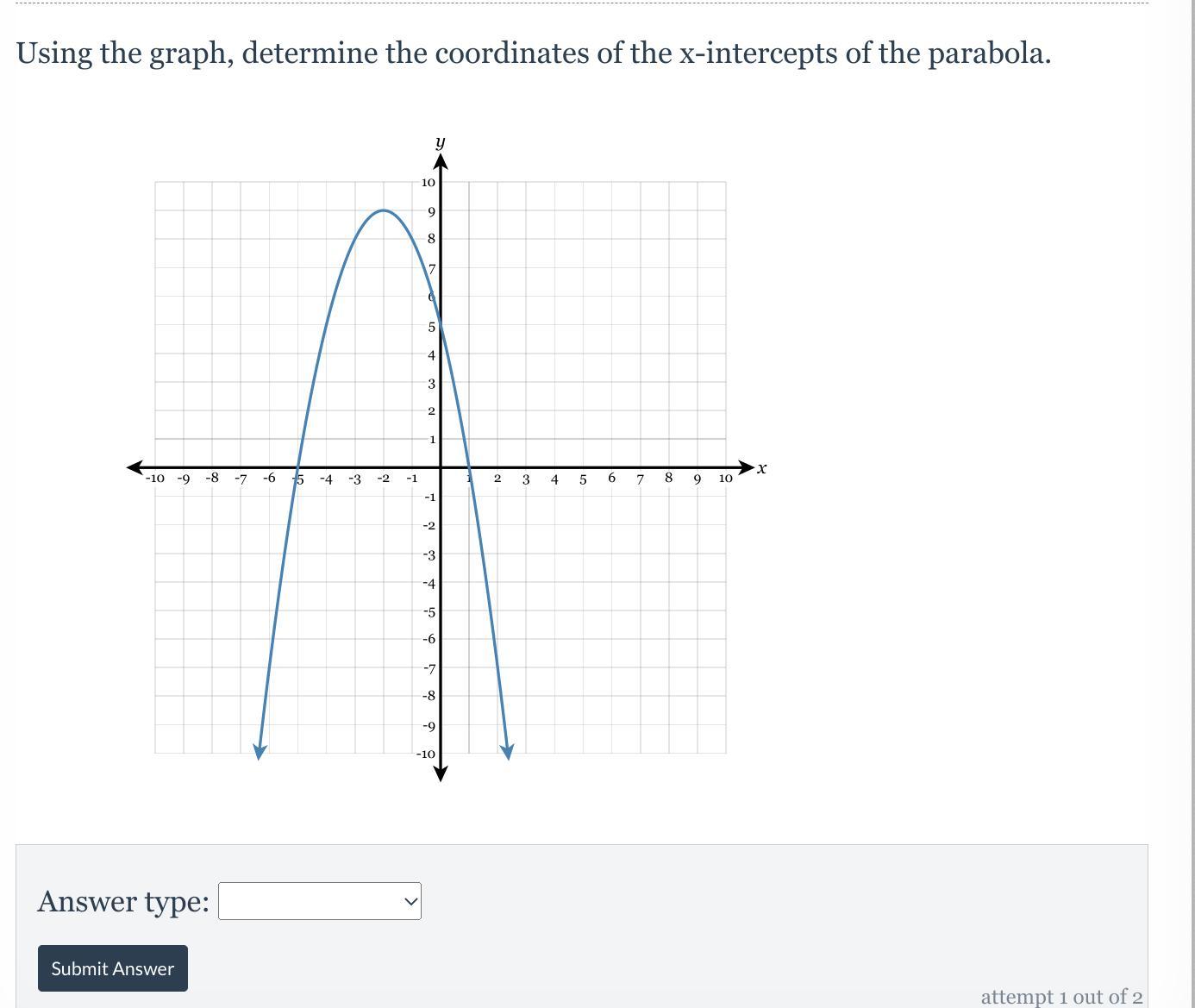
Using the graph, determine the coordinates of the x-intercepts of the parabola.
Answers
Answer:
x = -5, x = 1
As (x, y) coordinates, the x-intercepts are (-5, 0) and (1, 0).
Step-by-step explanation:
The x-intercepts are the x-values of the points at which the curve crosses the x-axis, so when y = 0.
From inspection of the given graph, we can see that the parabola crosses the x-axis at x = -5 and x = 1.
Therefore, the x-intercepts of the parabola are:
x = -5x = 1As (x, y) coordinates, the x-intercepts are (-5, 0) and (1, 0).
Related Questions
which statement is correct? group of answer choices assessment is only one part of the overall testing process. testing is only one part of the overall assessment process. testing integrates test information with information from other sources.
Answers
Testing is only one part of the overall assessment process.
What is evaluation in education?
Assessment is an ongoing process of gathering evidence of what each student actually knows, understands, and can do. A comprehensive evaluation approach includes a combination of formal and informal evaluation (formative, preliminary, and summative).
What is an assessment? Also what does it mean?
At the course level, assessments provide important data on the breadth and depth of student learning. Evaluation is more than scoring. It's about measuring student learning progress. Assessment is therefore defined as “the process of data gathering to better understand the strengths and weaknesses of a student's learning”.
Learn more about assessment
brainly.com/question/28046286
#SPJ1
need answer by 11:45am
The box plots display measures from data collected when 20 people were asked about their wait time at a drive-thru restaurant window.
A horizontal line starting at 0, with tick marks every one-half unit up to 32. The line is labeled Wait Time In Minutes. The box extends from 8.5 to 15.5 on the number line. A line in the box is at 12. The lines outside the box end at 3 and 27. The graph is titled Super Fast Food.
A horizontal line starting at 0, with tick marks every one-half unit up to 32. The line is labeled Wait Time In Minutes. The box extends from 9.5 to 24 on the number line. A line in the box is at 15.5. The lines outside the box end at 2 and 30. The graph is titled Burger Quick.
Which drive-thru typically has more wait time, and why?
Burger Quick, because it has a larger median
Burger Quick, because it has a larger mean
Super Fast Food, because it has a larger median
Super Fast Food, because it has a larger mean
Question 3
A charity needs to report its typical donations received. The following is a list of the donations from one week. A histogram is provided to display the data.
5, 5, 6, 8, 10, 15, 18, 20, 20, 20, 20, 20, 20
A graph titled Donations to Charity in Dollars. The x-axis is labeled 1 to 5, 6 to 10, 11 to 15, and 16 to 20. The y-axis is labeled Frequency. There is a shaded bar up to 2 above 1 to 5, up to 3 above 6 to 10, up to 1 above 11 to 15, and up to 7 above 16 to 20.
Which measure of variability should the charity use to accurately represent the data? Explain your answer.
The range of 13 is the most accurate to use, since the data is skewed.
The IQR of 13 is the most accurate to use, since the data is skewed.
The range of 20 is the most accurate to use to show that they have plenty of money.
The IQR of 20 is the most accurate to use to show that they need more money.
Question 4
The circle graph describes the distribution of preferred transportation methods from a sample of 400 randomly selected San Francisco residents.
circle graph titled San Francisco Residents' Transportation with five sections labeled walk 40 percent, bicycle 8 percent, streetcar 15 percent, bus 10 percent, and cable car 27 percent
Which of the following conclusions can we draw from the circle graph?
Together, Streetcar and Cable Car are the preferred transportation for 168 residents.
Together, Walk and Streetcar are the preferred transportation for 55 residents.
Bus is the preferred transportation for 45 residents.
Bicycle is the preferred transportation for 50 residents.
Question 5
The line plot displays the number of roses purchased per day at a grocery store.
A horizontal line starting at 1 with tick marks every one unit up to 10. The line is labeled Number of Rose Bouquets, and the graph is titled Roses Purchased Per Day. There is one dot above 1 and 2. There are two dots above 8. There are three dots above 6, 7, and 9.
Which of the following is the best measure of variability for the data, and what is its value?
The range is the best measure of variability, and it equals 8.
The range is the best measure of variability, and it equals 2.5.
The IQR is the best measure of variability, and it equals 8.
The IQR is the best measure of variability, and it equals 2.5.
Question 6
The histograms display the frequency of temperatures in two different locations in a 30-day period.
A graph with the x-axis labeled Temperature in Degrees, with intervals 60 to 69, 70 to 79, 80 to 89, 90 to 99, 100 to 109, 110 to 119. The y-axis is labeled Frequency and begins at 0 with tick marks every one unit up to 14. A shaded bar stops at 10 above 60 to 69, at 9 above 70 to 79, at 5 above 80 to 89, at 4 above 90 to 99, and at 2 above 100 to 109. There is no shaded bar above 110 to 119. The graph is titled Temps in Sunny Town.
A graph with the x-axis labeled Temperature in Degrees, with intervals 60 to 69, 70 to 79, 80 to 89, 90 to 99, 100 to 109, 110 to 119. The y-axis is labeled Frequency and begins at 0 with tick marks every one unit up to 16. A shaded bar stops at 2 above 60 to 69, at 4 above 70 to 79, at 12 above 80 to 89, at 6 above 90 to 99, at 4 above 100 to 109, and at 2 above 110 to 119. The graph is titled Temps in Desert Landing.
When comparing the data, which measure of center should be used to determine which location typically has the cooler temperature?
Median, because Desert Landing is symmetric
Mean, because Sunny Town is skewed
Mean, because Desert Landing is symmetric
Median, because Sunny Town is skewed
Question 7
At a recent baseball game of 5,000 in attendance, 150 people were asked what they prefer on a hot dog. The results are shown.
Ketchup Mustard Chili
63 27 60
Based on the data in this sample, how many of the people in attendance would prefer mustard on a hot dog?
900
2,000
2,100
4,000
Answers
The drive-thru with typically more wait time is Burger Quick, because it has a larger median. The Option A.
Why does Burger Quick have a larger median for wait time?The median is a measure of central tendency that represents the middle value of a set of data. In this case, the median wait time at Burger Quick is 15.5 minutes, while the median wait time at Super Fast Food is 12 minutes.
This indicates that, on average, customers at Burger Quick experience a longer wait time compared to customers at Super Fast Food. The larger median at Burger Quick suggests that there may be some longer wait times skewing the data towards the higher end which could be due to various factors such as slower service, or other operational issues at Burger Quick resulting in a longer wait time for customers at their drive-thru.
Read more about median
brainly.com/question/16408033
#SPJ1
in desperate need of help!! (i accidentally clicked the first answer)
Answers
Answer:
The answer is 28
Step-by-step explanation:
sin0=opp/hyp
let hyp be x
sin30=14/x
0.5x=14
divide both sides by 0.6
x=14/0.5
x=28
Can someone help me asap? It’s due tomorrow. I will give brainiest if it’s correct.
A. 23
B. 61
C. 37
D. 14
Answers
Answer: the answer is A. 14.
Step-by-step explanation: In each trial of the reenactment, Scott chooses one card from the stack and records its digit. Based on the given data, a digit of or 1 speaks to a objective scored, and a digit of 2 through 9 speaks to a missed endeavor.
Out of the 5 endeavors per amusement, on the off chance that Scott scores precisely 2 objectives, it implies he missed 3 endeavors. Subsequently, the likelihood of this occasion can be calculated as:
P(exactly 2 objectives) = (0.2)²(0.8)³ = 0.008192
This likelihood can be utilized to discover the anticipated number of diversions in which Scott scores precisely 2 objectives, by duplicating it by the overall number of diversions reenacted:
Anticipated number of recreations = P(exactly 2 objectives) × Add up to number of recreations = 0.008192 × 84 ≈ 0.68
Adjusting to the closest entire number, we get that Scott is anticipated to score precisely 2 objectives in 1 diversion out of the 84 recreated diversions.
Simplify these expressions
5×x
6×x×y
2×x×3×y
Answers
Answer:
5x
6xy
2x3y
hope it's helpful
5 cm
Find Surface Area. Rectangles use Aslw or Anbh. Triangles use A=1/ibb.
8 cm
cm
6 cm
2 cm
14
8 can
A=
12.m
12 cm
10 cm
C
First Part
Answers
The surface area of the two solids are listed below:
Case 1 - 232 square centimeters
Case 2 - 240 square centimeters
How to find the surface area of a solid
The surface area of a solid is the sum of the areas of all its faces. There are two cases of solids whose surface areas must be determined. The area formulas for triangle and rectangle are, respectively:
Triangle
A = 0.5 · b · h
Rectangle
A = b · h
Case 1
A = (6 cm) · (8 cm) + 2 · 0.5 · (6 cm) · (12 cm) + 2 · 0.5 · (8 cm) · (14 cm)
A = 232 cm²
Case 2
A = 2 · 0.5 · (8 cm) · (3 cm) + (8 cm) · (12 cm) + 2 · (5 cm) · (12 cm)
A = 24 cm² + 96 cm² + 120 cm²
A = 240 cm²
To learn more on surface areas of solids: https://brainly.com/question/31126484
#SPJ1
2. Which sequence of transformations takes the graph of y = k(x) to the graph of
y=-k(x + 1)?
A. Translate 1 to the right, reflect over the x-axis, then scale vertically by a factor of 1/2
B. Translate 1 to the left, scale vertically by 1/2 , then reflect over the y-axis.
C. Translate left by 1/2, then translate up 1.
D. Scale vertically by 1/2, reflect over the x-axis, then translate up 1.
Answers
The correct answer is option B. Translate 1 to the left, scale vertically by 1/2, then reflect over the y-axis.
What does term "transformation of a graph" means?The process of modifying the shape, location, or features of a graph is often referred to as graph transformation. Graphs are visual representations of mathematical functions or data point connections, often represented on a coordinate plane.
Translations, reflections, rotations, dilations, and other changes to the look of a graph are examples of graph transformations.
For the given problem, Transformation to get the desired result can be carried out as:
Translate '1' to the left: The transformation "x + 1" in "-k(x + 1)" shifts the graph horizontally to the left by 1 unit.Scale vertically by '1/2' : The 1/2 factor in "-k(x + 1)" vertically scales the graph, compressing it vertically.Reflect over the y-axis: The minus sign before "k" in "-k(x + 1)" reflects the graph over the y-axis, flipping it horizontally.Hence, to convert the graph of "y = k(x)" to the graph of "y = -k(x + 1)," the correct sequence of transformations is to translate 1 unit to the left, scale vertically by 1/2, and then reflect across the y-axis, which is option B.
Learn more about Graph Transformation here:
https://brainly.com/question/10059147
#SPJ1
A triangle has two legs measuring 21 cm and 20 cm. Which of the following leg measurement will make a right triangle?
Answers
The leg measurement will make a right triangle is 21 cm.
What is hypotenous?The longest side of a right-angled triangle, i.e. the side opposite the right angle, is called the hypotenuse in geometry.
Pythagorean theorem :
If p be the length of the hypotenuse of a right-angled triangle, q and r be the lengths of the other two sides, then
p² = q² + r²
The lengths of the other two sides of the given right-angled triangle are 20 cm and 21 cm. Put these values in the above theorem to get the desired result.
Now, p² = (20)² + (21)²
= 400 + 441 = 841
i.e. p = √(841) = 29
Therefore the length of the hypotenuse is 29 cm. The right angle traingle is 21 cm.
Learn more about hypotenuse, here:
https://brainly.com/question/28946097
#SPJ1
which of the following null hypothesis statistical tests require calculating degrees of freedom? group of answer choices all of the above two-sample t-test chi-squared one-sample t-test
Answers
The two null hypothesis that are correct answer are two-sample t-test and one-sample t-test.
Among the group of answer choices provided, the tests that require calculating degrees of freedom are the two-sample t-test and the one-sample t-test. Both of these tests belong to the t-test family and involve using degrees of freedom to determine the critical t-value.
In summary:
- Null hypothesis: The assumption that there is no significant difference between the sample and population or between two samples.
- T-test: A statistical test used to determine if there is a significant difference between the means of two groups or between a sample and population mean.
- Degrees of freedom: A value used in statistical tests that represents the number of independent values in a data set, which can affect the outcome of the test.
So answer is: two-sample t-test and one-sample t-test.
Learn more about null hypothesis here:
https://brainly.com/question/28920252
#SPJ11
The null hypothesis statistical tests that require calculating degrees of freedom are the two-sample t-test and the one-
sample t-test. The degrees of freedom are necessary to calculate the t-value for these tests. The chi-squared test also
requires degrees of freedom, but it is not a test for a null hypothesis.
The correct answer is: all of the above.
All these tests require calculating degrees of freedom:
1. Two-sample t-test:
Degrees of freedom are calculated using the formula (n1 + n2) - 2, where n1 and n2 are the sample sizes of the two
groups being compared.
2. Chi-squared test:
Degrees of freedom are calculated using the formula (rows - 1) * (columns - 1), where rows and columns represent the
number of categories in the data.
3. One-sample t-test:
Degrees of freedom are calculated using the formula n - 1, where n is the sample size.
The null hypothesis statistical tests that require calculating degrees of freedom are the two-sample t-test and the one-
sample t-test. The degrees of freedom are necessary to calculate the t-value for these tests. The chi-squared test also
requires degrees of freedom, but it is not a test for a null hypothesis.
for such more question on null hypothesis
https://brainly.com/question/4436370
#SPJ11
in a(n) , the scale questions are divided into two parts equally and the resulting scores of both parts are correlated against one another.
Answers
The main topic is the split-half reliability test used in psychological research to assess the internal consistency of a scale.
How to test the psychological research?In psychological research, reliability is a crucial aspect of measuring constructs or attributes. One commonly used method for assessing the reliability of a scale is the split-half reliability test.
In this test, the scale questions are divided into two parts equally, and the resulting scores of both parts are correlated against one another.
For example, if a scale had 20 items, the items could be randomly split into two groups of 10 items each.
Scores are then calculated for each group, and the scores are correlated with each other to determine the degree of consistency between the two halves.
The correlation coefficient obtained from this analysis provides an estimate of the internal consistency of the scale.
A high correlation coefficient indicates a high level of internal consistency, indicating that the two halves of the scale are measuring the same construct or attribute.
Conversely, a low correlation coefficient suggests that the two halves of the scale are not measuring the same construct or attribute, and the scale may need to be revised or abandoned.
Overall, the split-half reliability test provides a quick and efficient method for evaluating the reliability of a scale.
However, it is important to note that this method does have some limitations, such as the possibility of unequal difficulty or discrimination of the items in each half of the scale.
Therefore, researchers often use other methods, such as Cronbach's alpha, in conjunction with the split-half reliability test to provide a more comprehensive assessment of the reliability of a scale
Learn more about reliability test
brainly.com/question/27873337
#SPJ11
Hello solve this, what is 9 x 5/7
Answers
Answer: 6 3/7
Step-by-step explanation:
9/1 x 5/7
If we multiply the numerators and denominators, we get 45/7 or 6 3/7 as a mixed number.
Answer:
[tex]\frac{45}{7}[/tex] or 6.4285
Step-by-step explanation:
First, multiply 9 and 5, which gives you 45.
9(5)=45
Then, divide 45 by 7.
45/7=6.4285
That gives you [tex]\frac{45}{7}[/tex] or 6.4285
Hope this helps!
g a generic drug is being tested to test its efficacy (effectiveness) at reducing blood pressure in patients with hypertension (a.k.a. high blood pressure). in a randomized, double-blind experiment with 200 patients, 100 are given the name-brand drug (control group) and 100 are given a generic version of the drug (treatment group). in the control group, the average reduction in blood pressure is 15.2 mmhg with a standard deviation of 11.5 mmhg. in the treatment group, there is an average reduction of 14.6 mmhg and a standard deviation of 12.5 mmhg. neither group has any outliers. a researcher claims that this study shows the generic drug is not as effective as the name-brand drug. what would be the reply of a statistician? you have two attempts for this problem so choose wisely. if you do not receive 5 points in the gradebook after submitting this assignment then you have answered incorrectly. make sure to try it again before the deadline.
Answers
A statistician would reply that in order to determine if the generic drug is less effective than the name-brand drug, a hypothesis test needs to be conducted.
The null hypothesis (H0) would be that there is no difference in the average blood pressure reduction between the two drugs, while the alternative hypothesis (H1) would be that the name-brand drug has a higher average reduction in blood pressure than the generic drug.
To test these hypotheses, a t-test would be appropriate since we have two independent samples (control and treatment groups) with known means, standard deviations, and sample sizes. The t-test will provide a p-value, which can be compared to a chosen significance level (e.g., α = 0.05).
If the p-value is less than the significance level, we reject the null hypothesis and conclude that there is a significant difference in the average blood pressure reduction between the two drugs. If the p-value is greater than the significance level, we fail to reject the null hypothesis, meaning we do not have enough evidence to claim that the name-brand drug is more effective than the generic drug.
Learn more about hypothesis:
https://brainly.com/question/10854125
#SPJ11
rylie is a newly hired cybersecurity expert for a government agency. rylie used to work in the private sector. she has discovered that, whereas private sector companies often had confusing hierarchies for data classification, the government's classifications are well known and standardized. as part of her training, she is researching data that requires special authorization beyond normal classification. what is this type of data called? group of answer choices
Answers
Compartmentalized is the type of data that is discussed in the problem researched by an employee rylie who is a newly hired cybersecurity expert for a government agency and has working experience in the private sector.
Data classification is the way of organizing data into different categories that make it easy to retrieve, sort and store for future use. In simple words, compartmentalization means to separate into isolated compartments or categories. In data language, A nonhierarchical grouping of information used to control access to data more finely than with hierarchical security classification alone is called Compartmentalization. Now, we have a rylie who is a newly hired cybersecurity expert for a government agency. She has working experience in the private sector. On basis of her experience she has discovered that, the private sector companies often had confusing hierarchies for data classification as compared to the government's classifications which are well known and standardized. During her training, she is researching data that requires special authorization beyond normal classification. The data type that she researched and that is authorization beyond normal classification is called compartmentalized data.
For more information about data classification, visit :
https://brainly.com/question/30580761
#SPJ4
Quilt squares are cut on the diagonal to form triangular quilt pieces. The hypotenuse of the resulting triangles is 20 inches long. What is the side length of each piece?
1. 10√2
2. 20√2
3. 10√3
4. 20√3
Answers
Answer:
The correct answer is:
10√2
Explanation:
In a right triangle, the hypotenuse is the side opposite the right angle and is also the longest side. The other two sides are called the legs.
In this problem, the hypotenuse of the resulting triangles is given as 20 inches. Since the quilt squares are cut on the diagonal to form triangular quilt pieces, the hypotenuse of each triangle is formed by the diagonal cut of a square.
Let's denote the side length of each square as "s" inches.
According to the Pythagorean Theorem, which relates the sides of a right triangle, the square of the length of the hypotenuse is equal to the sum of the squares of the lengths of the two legs.
In this case, the hypotenuse is 20 inches, so we have:
20^2 = s^2 + s^2 (since the two legs of the right triangle are the sides of the square)
400 = 2s^2
Dividing both sides by 2, we get:
200 = s^2
Taking the square root of both sides, we get:
s = √200
Since we are looking for the side length of each piece in simplified radical form, we can further simplify √200 as follows:
√200 = √(100 x 2) = 10√2
So, the side length of each quilt piece is 10√
The side length of each piece of the triangular pieces of quilt cut from squares will be 10√2 inches.
This is a simple mathematics problem that can be solved using the Pythagoras theorem. This theorem states that in a right-angled triangle, the square root of the sum of the two perpendicular sides (p,b) is equal to the longest side, called the hypotenuse (h).
[tex]h = \sqrt{p^2 + b^2}[/tex]
Since the triangle pieces have been cut from a square, they will be right-angled triangles, and the two perpendicular sides will be equal, i.e., p = b.
20 = √2p² (since p and b are equal, b can be taken as p)
On squaring both sides,
400 = 2p²
p² = 400/2
p² = 200
p = √200
p = 10√2 = b
To know more about Pythagoras theorem,
https://brainly.com/question/28981380
Jackie has $500 in a savings account.The interest rate is 5% per year and is not compounded. How much will she have in total in 1 year?
Answers
Answer:
$525
Step-by-step explanation:
Jackie starts with $500, and the interest rate is 5% per year.
This means that, after one year, Jackie will have accumulated 5% interest with the $500 she put into the savings account.
Now, we can find 5% of $500 by converting 5% to its fraction form, which is 5/100. 5% of a value means that you need to multiply the fraction (or decimal) by the said value. So, we have:
[tex]\frac{5}{100}[/tex] · 500 =
[tex]\frac{2500}{100}[/tex] =
25
Therefore, the amount of interest she has accumulated in one year is $25. Combined with the money in her savings account, she has $525, since $500 + $25 = $525.
fractions to decimals
Answers
Answer: 1 is .4
2. is .6
3 is .5
4 is .375
5 is .18
6 is .71
7 is .16
8 is .66 repeating
9 is .91
and 10 is .25
Step-by-step explanation:
to get all these and fractions to decimals in the future just divide the numerator by the denominator in other words the top number by the bottom number
1): 0.4
2): 0.67 or 0.7
3): 0.5
4): 0.37 or 0.4
5): 0.18
6): 0.42 or 0.5
7): 0.17
8): 0.7
9): 0.97 or 1
10): 0.25
the profit p (in dollars) generated by selling x units of a certain commodity is given by the function p ( x ) = - 1500 + 12 x - 0.004 x ^ 2 What is the maximum profit, and how many units must be sold to generate it?
Answers
The profit (p) is $7500 generated by selling 1500 units of a certain commodity is given by the function p ( x ) = - 1500 + 12 x - 0.004 x²
To maximize our profit, we must locate the vertex of the parabola represented by this function. The x-value of the vertex indicates the number of units that must be sold to maximize profit.
We may use the formula for the x-coordinate of a parabola's vertex:
x = -b/2a
where a and b represent the coefficients of the quadratic function ax² + bx + c. In this situation, a = -0.004 and b = 12, resulting in:
x = -12 / 2(-0.004) = 1500
This indicates that when 1,500 units are sold, the profit is maximized.
To calculate the greatest profit, enter x = 1500 into the profit function:
P(1500) = -1500 + 12(1500) - 0.004(1500)^2
P(1500) = -1500 + 18000 - 9000
P(1500) = $7500
Therefore, the maximum possible profit is $7,500 and it is generated when 1,500 units are sold.
Learn more about Profit maximization:
https://brainly.com/question/30436087
#SPJ4
To achieve this maximum profit, exactly 1500 units must be sold.
To find the maximum profit and the number of units needed to generate it, we can use the given profit function p(x) = -1500 + 12x - 0.004x^2. We need to find the vertex of the parabola represented by this quadratic function, as the vertex will give us the maximum profit and the corresponding number of units.
Step 1: Identify the coefficients a, b, and c in the quadratic function.
In p(x) = -1500 + 12x - 0.004x^2, the coefficients are:
a = -0.004
b = 12
c = -1500
Step 2: Find the x-coordinate of the vertex using the formula x = -b / (2a).
x = -12 / (2 * -0.004) = -12 / -0.008 = 1500
Step 3: Find the maximum profit by substituting the x-coordinate into the profit function p(x).
p(1500) = -1500 + 12 * 1500 - 0.004 * 1500^2
p(1500) = -1500 + 18000 - 0.004 * 2250000
p(1500) = -1500 + 18000 - 9000
p(1500) = 7500
So, the maximum profit is $7,500, and 1,500 units must be sold to generate it.
To learn more about parabola: brainly.com/question/8227487
#SPJ11
answer asap, 12 points !!!
Answers
Answer:
Step-by-step explanation:
domain is -infinity to positive infinity range is -3 to infinity. Increasing from -3 to infinity and decreasing from - infinity to -3 and it’s minimum
how many intervals (or 'bins' or 'classes') should be chosen when creating a histogram? question 1 options: most often, about 8-10. eleven. it can vary - it really depends on the distribution of the variable. a minimum of 5.
Answers
"It can vary - it really depends on the distribution of the variable."
The number of intervals, or bins, to choose when creating a histogram can vary depending on the distribution of the variable.
Most often, about 8-10 intervals are used, but there is no set rule. It is generally recommended to have at least 5 intervals, but if the data is highly skewed or has outliers, more intervals may be needed to accurately represent the distribution.
Ultimately, the goal is to choose a number of intervals that provides a clear visual representation of the data without oversimplifying or overcomplicating the histogram.
The number of intervals or bins to be chosen when creating a histogram can vary and it really depends on the distribution of the variable.
While most often, about 8-10 bins are used, there is no hard and fast rule for the number of bins to be used in a histogram.
In general, the number of bins should be large enough to display the shape of the distribution clearly, but not so large that it obscures important features of the distribution or leads to overfitting.
A minimum of 5 bins is recommended to display the basic shape of the distribution, but more bins may be necessary for complex or multi-modal distributions.
Depending on the distribution of the variable, a histogram's number of intervals or bins can be altered.
There is no established guideline, however 8–10 intervals are typically utilized.
A minimum of five intervals are often advised, however if the data is extremely skewed or contains outliers, more intervals could be required to correctly depict the distribution.
For similar questions on variable.
https://brainly.com/question/27894163
#SPJ11
Using trig to find angles.
Solve for x. Round to the nearest tenth of a degree, if necessary.
Answers
Answer:
x ≈ 39.5°
Step-by-step explanation:
using the cosine ratio in the right triangle
cos x = [tex]\frac{adjacent}{hypotenuse}[/tex] = [tex]\frac{OP}{NP}[/tex] = [tex]\frac{64}{83}[/tex] , then
x = [tex]cos^{-1}[/tex] ( [tex]\frac{64}{83}[/tex] ) ≈ 39.5° ( to the nearest tenth )
Please answer the question in the pdf. I just need the values for A, B, and C. I am offering 15 points. Thanks.
Answers
Recall the equation provided in the pdf:
(125x ^ 3 * y ^ - 12) ^ (- 2/3) = (y ^ [A])/([B] * x ^ [c])
find A B and C.
The answer will be:
A = 8/3B = 3/4C = 8/3Checkout the calculation of the exponentialWe can solve this problem using the rules of exponents and algebraic manipulation.
Starting with the left-hand side of the equation:
(125x^3 * y^-12)^(-2/3)
Using the rule that (a * b)^c = a^c * b^c, we can rewrite the expression as:
125^(-2/3) * x^(-2) * y^(8)
Simplifying further, we can use the fact that a^(-n) = 1/(a^n) to get:
1/(5^2 * x^2 * y^8/3)
Now, we can see that the denominator on the right-hand side of the equation must be 5^2 * x^2 * y^8/3. To find the numerator, we need to simplify the expression y^A. Comparing exponents, we see that:
y^A = y^(8/3)
Therefore, we need to find a value of A such that A = 8/3. Solving for A, we get:
A = 8/3
Now, we can write the equation as:
y^(8/3)/(5^2 * x^2 * y^8/3) = y^(8/3)/(25 * x^2 * y^(8/3))
Comparing exponents again, we see that we need to find values of B and C such that:
B * C = 2
and
-8/3 = -C
Solving for C, we get:
C = 8/3
Substituting this value of C into the first equation, we get:
B * 8/3 = 2
Solving for B, we get:
B = 3/4
Therefore, the solution is:
A = 8/3
B = 3/4
C = 8/3
Learn more about exponential algebra here:
https://brainly.com/question/12940982
#SPJ1
<
1. Decide if each quadrilateral is a paranciogram. Explain
1 Pt
105
DOOOO
B
A
75
DE
1 Pt
OO
A B
4/7 -
11
65°
E
1 Pt.
For what value of x must the quadrilateral be a parallelogram?
A
O
B
с D E
A. Yes the quadrialateral is a parallelogram, because consecutive angle are supplementary.
B. Yes the quadrialateral is a parallelogram, because one pair of opposites sides is both
parallel and congruent
C. Yes the quadrialateral is a parallelogram, because opposite angles are congruent.
D. Yes the quadrialateral is a parallelogram, because diagonals bisect each other.
E. No we do not have enough information to prove this is a parallelogram.
IF YOU CAN HELP WITH SCHOOL FOR $ PLEASE ASK FOR MY CONTACT IN COMMENTS
Answers
For all given Quadrilaterals none has enough information provided in the problem to definitively say - if they are a parallelogram.Hence, option E is correct for all.
How to determine if Quadrilateral is a parallelogram?If a quadrilateral is a parallelogram, it satisfies the following properties:
Opposite sides are parallel.Opposite sides are equal in length.Opposite angles are equal.Diagonals bisect each other.It is important to note that in order to definitively conclude that a quadrilateral is a parallelogram, all four properties must be satisfied. If only one or some of the properties are met, it does not necessarily guarantee that the quadrilateral is a parallelogram.
Figure 1-: Adjacent angles are 105 and 75 degrees, which satify the condition of opposite angles being equal but except this no other information is provided, Hence, we don't have enough information to say figure 1 is a parallelogram.
Figure 2-: Diagonals bisect each other and make angle 65 degree with each other. Given that Diagonal 1 bisects Diagonal 2 and the opposite sides of the quadrilateral are equal, by using SAS criterion, the congruency of triangles formed by the diagonals can be derived to say that the opposite angles of the quadrilateral are also equal . However, we still need more information about parallelism of sides to definitively say given quadrilateral is a parallelogram.
Figure 3-: One pair of opposite side is equal in length ,while other pair of line is parallel to each other.This information is insufficient to determine if given quadrilateral is a parallelogram.
Learn more about parallelogram here:
https://brainly.com/question/29147156
#SPJ1
help me please like right now as soon as possible write the answer in terms of pi and round the answer to the nearest hundredths place I will give branliest
Answers
Thus, the total surface area of cylinder is found to be 480π sq. cm.
Explain about the surface area of cylinder:A cylinder's surface area is made up of its two congruent, parallel circular sides added together with its curved surface area. You must determine the Base Area (B) and Curved Surface Area in order to determine the surface area of a cylinder (CSA).
As a result, the base area multiplied by two and the area of a curved surface add up to the surface area or total surface of a cylinder.
Given data:
radius r = 8 cm
Height h = 22 cm
Total surface area of cylinder = 2*area of circle + area of curved cylinder
TSA = 2πr² + 2πrh
TSA = 2π(8)² + 2π(8)(22)
TSA = 2π(64) + 2π(176)
TSA = 128π + 352π
TSA = 480π sq. cm.
Thus, the total surface area of cylinder is found to be 480π sq. cm.
Know more about the surface area of cylinder:
https://brainly.com/question/27440983
#SPJ1
Complete question-
Find the surface area of the cylinder with radius of 8 cm and height of 22 cm. write the answer in terms of pi and round the answer to the nearest hundredths place.
a random sample of n equal to 64 scores is selected from a normally distributed population with mu equal to 77 and sigma equal to 21. what is the probability that the sample mean will be less than 79? hint: this is a z-score for a sample.
Answers
The probability of the sample mean being less than 79 is 77.64%
In order to solve the given problem we have to take the help of Standard error mean
SEM = ∑/√(n)
here,
∑ = population standard deviation
n = sample size
hence, the z-score can be calculated as
z = ( x' - μ)/σ/√(n)
here,
x' = sample mean
μ = population mean
σ = population standard deviation
n = sample size
adding the values into the formula
SEM = σ / √(n)
= 21/√64
= 2.625
z = (x' - μ)/SEM
= (79-77)/2.625
= 0.76
now, using standard distribution table we find that probability of a z-score is less than 0.77 then converting it into percentage
0.77 x 100
= 77%
The probability of the sample mean being less than 79 is 77.64%
To learn more about probability,
https://brainly.com/question/13604758
#SPJ4
Question A scale model of a ramp is a right triangular prism as given in this figure. In the actual ramp, the triangular base has a height of 0.6 yards. What is the surface area of the actual ramp, including the underside? Enter your answer as a decimal in the box. yd² Right triangular prism. Each base is a triangle whose legs are 8 in, 5 in, and 5 in. The height of the triangles is 3 in. The prism is oriented so that the side labeled 8 in is on the bottom. The distance between the bases is labeled 4 in.
Answers
The surface area of the actual ramp, including the underside, is approximately 15.38 yd².
What is triangle?
A triangle is a three-sided polygon with three angles. It is a fundamental geometric shape and is often used in geometry and trigonometry.
To find the surface area of the actual ramp, we need to first find the dimensions of the ramp.
We are given that the scale model of the ramp is a right triangular prism with legs of 8 in, 5 in, and 5 in, and a height of 3 in. We can use these dimensions to find the dimensions of the actual ramp.
Since the ramp is a scale model, the ratio of the dimensions of the model to the actual ramp is the same for all corresponding dimensions. The height of the triangular base in the actual ramp is given as 0.6 yards, which is equal to 21.6 inches. So, we have:
height of actual ramp / height of model = 21.6 in / 3 in = 7.2
We can use this ratio to find the dimensions of the actual ramp:
height of actual ramp = 7.2 * 3 in = 21.6 in
length of actual ramp = 7.2 * 8 in = 57.6 in
width of actual ramp = 7.2 * 5 in = 36 in
Now we can find the surface area of the actual ramp. The surface area of the top and bottom of the ramp is the area of the triangular base plus the area of the rectangle formed by the length and width of the ramp:
Area of triangular base = (1/2) * base * height = (1/2) * 5 in * 5 in = 12.5 in²
Area of rectangular top and bottom = length * width = 57.6 in * 36 in = 2073.6 in²
Total surface area of top and bottom = 2 * (Area of triangular base + Area of rectangular top and bottom) = 2 * (12.5 in² + 2073.6 in²) = 4153.2 in²
The surface area of the sides of the ramp is the area of the three rectangles formed by the height and width of the ramp:
Area of one side rectangle = height * width = 21.6 in * 36 in = 777.6 in²
Total surface area of sides = 3 * Area of one side rectangle = 3 * 777.6 in² = 2332.8 in²
Finally, we add the surface area of the top and bottom to the surface area of the sides to get the total surface area of the ramp:
Total surface area of ramp = Surface area of top and bottom + Surface area of sides = 4153.2 in² + 2332.8 in² = 6486 in²
Converting to yards and rounding to two decimal places, we get:
Total surface area of ramp = 6486 in² / (36 in/yd)² = 15.38 yd² (rounded to two decimal places)
Therefore, the surface area of the actual ramp, including the underside, is approximately 15.38 yd².
To learn more about triangle from the given link:
https://brainly.com/question/2773823
#SPJ1
Write the functions in standard form:
h(x)=2(x-3)²-9
h(x)=
p(x) = -5(x + 2)² + 15
p(x)=
Answers
Answer:
[tex]h(x)=2x^2-12x+9[/tex], [tex]p(x)=-5x^2-20x-5[/tex]
Step-by-step explanation:
To get to the standard form of a quadratic equation, we need to expand and simplify. Recall that standard form is written like so:
[tex]ax^2+bx+c[/tex]
Where a, b, and c are constants.
Let's expand and simplify h(x).
[tex]2(x-3)^2-9=\\2(x^2+9-6x)-9=\\2x^2+18-12x-9=\\2x^2+9-12x=\\2x^2-12x+9[/tex]
Thus, [tex]h(x)=2x^2-12x+9[/tex]
Let's do the same for p(x).
[tex]-5(x+2)^2+15=\\-5(x^2+4+4x)+15=\\-5x^2-20-20x+15=\\-5x^2-5-20x=\\-5x^2-20x-5[/tex]
Thus, [tex]p(x)=-5x^2-20x-5[/tex]
Solve for x. -7.6 -1.2 + X 0.5
Answers
-7.6 - 1.2 + x = 0.5
Adding -7.6 and -1.2, we get:
-8.8 + x = 0.5
Now we can isolate x by adding 8.8 to both sides of the equation:
-8.8 + x + 8.8 = 0.5 + 8.8
Simplifying, we get:
x = 9.3
Therefore, the solution for x in the equation -7.6 - 1.2 + x = 0.5 is x = 9.3.
Find the value of x .
J
30°
M
to
K
(2x - 30)°
[
Answers
The value of x in the Intersecting chords is 15
Finding the value of x .From the question, we have the following parameters that can be used in our computation:
Intersecting chords
The value of x is then calculated as
x = 1/2(30 - 2x + 30)
So, we have
2x = 30 - 2x + 30
Evaluate the like terms
4x = 60
Divide
x = 15
Hence, the value of x is 15
Read more about angles at
https://brainly.com/question/28293784
#SPJ1
A bottle of water that is 80°F is placed in a cooler full of ice. The temperature of the water decreases by 0. 5°F every minute. What is the temperature of the water, in degrees Fahrenheit, after 5 1/2
minutes? Express your answer as a decimal
Answers
After 5 and a half minutes, the temperature of the water will be 77°F.
In this scenario, we are given that the initial temperature of the water is 80°F. We also know that the temperature of the water decreases by 0.5°F every minute. We want to find out what the temperature of the water will be after 5 and a half minutes.
To solve this problem, we need to use a bit of math. We know that the temperature of the water is decreasing by 0.5°F every minute. So after 1 minute, the temperature of the water will be 80°F - 0.5°F = 79.5°F. After 2 minutes, the temperature will be 79.5°F - 0.5°F = 79°F. We can continue this pattern to find the temperature after 5 and a half minutes.
After 5 minutes, the temperature of the water will be 80°F - (0.5°F x 5) = 77.5°F. And after another half minute (or 0.5 minutes), the temperature will decrease by another 0.5°F, so the temperature will be 77.5°F - 0.5°F = 77°F.
To know more about temperature here
https://brainly.com/question/11464844
#SPJ4
A $2 coin with a diameter of 25. 75 mm. How many turns does such a piece make if you roll it on the edge for 1. 34 m?
Answers
The coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
How to find the number of turns the coin makes?The circumference of the coin can be calculated as follows to determine the number of turns it makes:
C = πd
where C is the circumference, d is the diameter, and π is the mathematical constant pi (approximately equal to 3.14159).
So, for the given $2 coin with a diameter of 25.75 mm, the circumference is:
C = πd = 3.14159 x 25.75 mm ≈ 80.926 mm
Divide the distance traveled by the coin's circumference to determine the number of turns it makes when rolled on its edge for 1.34 meter:
Number of turns = distance traveled / circumference of the coin
Number of turns = 1.34 m / 0.080926 m
Number of turns ≈ 16.53
Therefore, the coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
know more about circumference visit :
https://brainly.com/question/28757341
#SPJ1