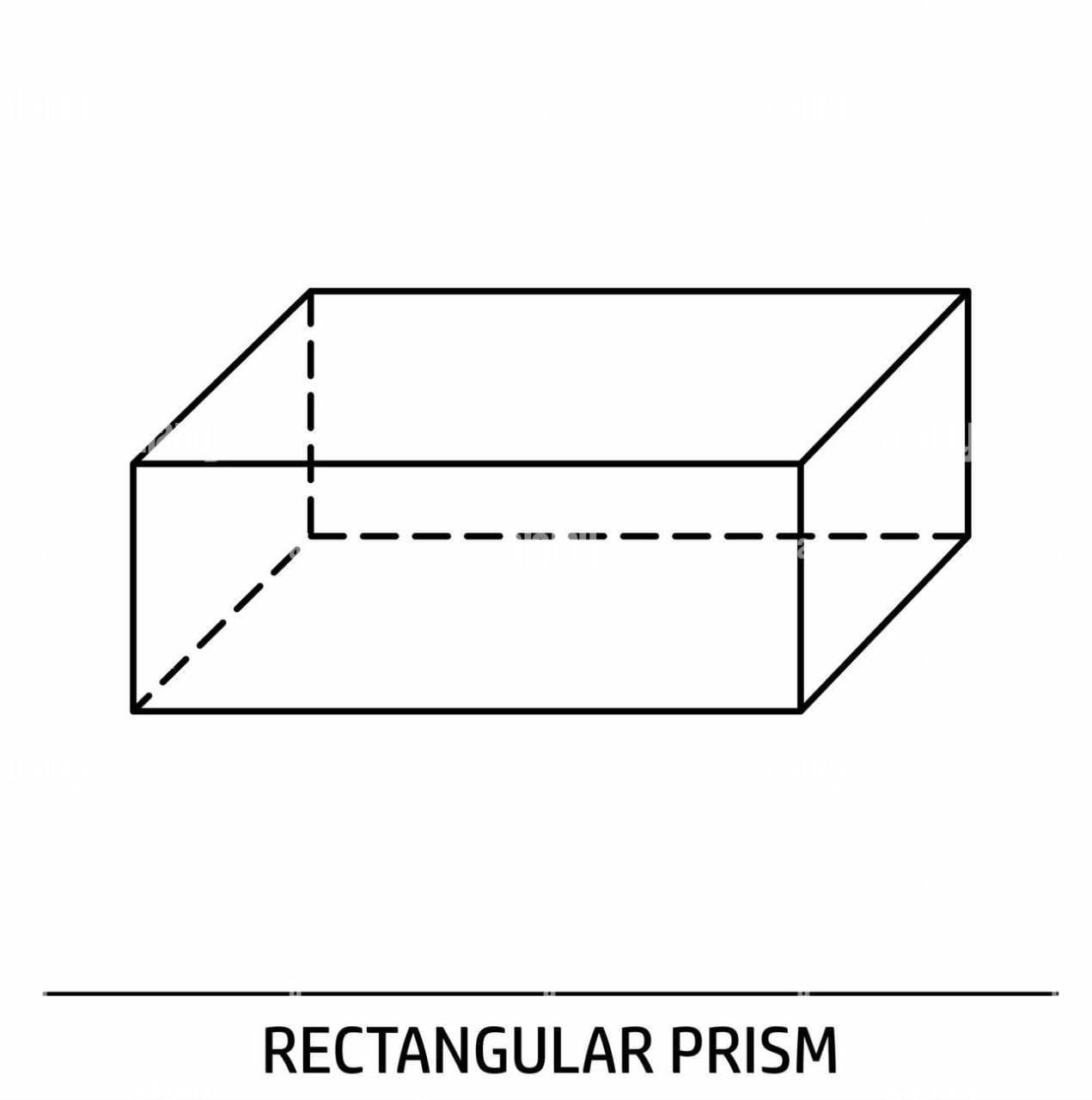
A rectangular prism is shown in the image.
A rectangular prism with dimensions of 5 yards by 5 yards by 3 and one half yard.
What is the volume of the prism?
Answers
Therefore, the volume of the rectangular prism is 87.5 cubic yards.
What is prism?A prism is a transparent object, usually made of glass or plastic, that refracts or bends light as it passes through it. It has at least two flat surfaces, called faces, that are usually parallel and rectangular in shape, and two non-parallel faces, called bases, which are usually triangular in shape. When light enters a prism, it is refracted, or bent, as it passes through the prism and is separated into its component colors, creating a rainbow effect. Prisms are often used in optics and science experiments to study the properties of light, such as its wavelength and polarization. They are also commonly used in optical instruments such as binoculars, telescopes, and cameras to help focus and direct light.
The volume V of a rectangular prism is given by the formula:
V = length x width x height
In this case, the length is 5 yards, the width is also 5 yards, and the height is 3- and one-half yard.
To calculate the volume, we can plug this value into the formula:
V = 5 yards x 5 yards x 3.5 yards
Simplifying this expression, we get:
V = 87.5 cubic yards
To learn more about prism, visit
https://brainly.com/question/29722724
#SPJ1
Answer:
The volume of a rectangular prism is the product of its length, width, and height. In this case, the length is 5 yards, the width is 5 yards, and the height is 3.5 yards. Therefore, the volume of the prism is 5 * 5 * 3.5 = 87.5 cubic yards.
Here is the calculation:
Volume = length * width * height
= 5 yards * 5 yards * 3.5 yards
= 87.5 cubic yards
Step-by-step explanation:
Related Questions
Homework 18.1.-trigonometric ratios
Find the 3 trigonometric ratios. If needed, reduce fractions.
Answers
Step-by-step explanation:
rotate the triangle in your mind (or as actual picture on your phone or computer), so that the right angle is the bottom right or bottom left, and C being the opposite bottom angle.
then we see
28 = cos(C) × 35
21 = sin(C) × 35
and so,
sin(C) = 21/35 = 3/5
cos(C) = 28/35 = 4/5
tan(C) = sin(C)/cos(C) = 3/5 / 4/5 = 3/4
how many non-empty subsets s of {1, 2, 3, . . . , 8} are there such that the product of the elements of s is at most 200?
Answers
The total number of non-empty subsets s of[tex]{1, 2, 3, . . . , 8}[/tex] such that the product of the elements of s is at most 200 is:
[tex]255 - (127 + 63 + 31) + 2 = 36.[/tex]
So, there are 36 such subsets.
Number of non-empty subsets s of[tex]{1, 2, 3, . . . , 8}[/tex] such that the product of the elements of s is at most 200, we can use a method called inclusion-exclusion principle.
First, we need to count the total number of non-empty subsets of the given set.
Since each element can either be included or excluded, there are [tex]2^8 - 1 = 255[/tex] non-empty subsets.
Next, we need to count the number of subsets whose product is greater than 200.
We can start by considering the subsets that contain 8, since 8 is the largest element in the set.
There are only two such subsets: {8} and {1, 8}.
Both of these subsets have a product greater than 200. Similarly, we can consider subsets that contain 7, and so on. We find that there are[tex]2^7 - 1 = 127[/tex] subsets that contain 7, and each of these subsets has a product greater than 200. Similarly, there are [tex]2^6 - 1 = 63[/tex] subsets that contain 6, and each of these subsets has a product greater than 200.
Double-counted the subsets that contain both 6 and 7, as well as those that contain both 6 and 8, and those that contain both 7 and 8.
Subtract the number of subsets that contain both 6 and 7, both 6 and 8, and both 7 and 8.
There are [tex]2^5 - 1 = 31[/tex] subsets that contain both 6 and 7, and each of these subsets has a product greater than 200.
Similarly, there are[tex]2^5 - 1 = 31[/tex] subsets that contain both 6 and 8, and each of these subsets has a product greater than 200.
Finally, there are [tex]2^5 - 1 = 31[/tex] subsets that contain both 7 and 8, and each of these subsets has a product greater than 200.
However, we have subtracted too much, since we have now excluded subsets that contain all three of 6, 7, and 8. There are only two such subsets: {6, 7, 8} and {1, 6, 7, 8}. Both of these subsets have a product greater than 200.
For similar questions on subsets
https://brainly.com/question/28705656
#SPJ11
To find the number of non-empty subsets s of {1, 2, 3, . . . , 8} such that the product of the elements of s is at most 200, we can use the concept of power set and combinatorics. By analyzing the pattern, we can determine that there are a total of 120 subsets whose product is at most 200.
Explanation:To find the number of non-empty subsets s of the set {1, 2, 3, . . . , 8} such that the product of the elements of s is at most 200, we can use the concept of power set and combinatorics. The power set of a set is the set of all its subsets. We know that the number of elements in the power set of a set with n elements is 2n. In this case, we have 8 elements in the set, so the power set will have 28 = 256 subsets. However, we need to find the number of subsets with a product at most 200.
We can analyze the products of all subsets to determine the count.
By analyzing the pattern, we can determine that there are a total of 120 subsets whose product is at most 200. This can be calculated by summing the total number of subsets for each number of elements (1-element subsets + 2-element subsets + 3-element subsets + ... + 8-element subsets).
https://brainly.com/question/33319261
#SPJ12
Special Right Triangles (Radical Answers)
The triangle below is equilateral. Find the length of side x in simplest radical form with a rational denominator.
Answers
The triangle is given as equilateral and the length of the perpendicular of the given equilateral triangle is 13.85.
What is Pythagorean theorem?It states that the sum of the squares of the two shorter sides of a right triangle is equal to the square of the hypotenuse, the longest side of the triangle. This theorem can be used to determine the length of the sides of a right triangle if two sides are known.
The triangle is given as equilateral. As we know he perpendicular in a equilateral triangle divides a line into to equal parts, so
Base= 8+8
= 16
As it is a equilateral triangle, all the sides will be equal.
Now, we can use the Pythagorean theorem to find the length of the perpendicular, which can be found by using the formula:
16²= 8² + x²
x² = 16²- 8²
x = √192
x = 13.85
Thus, the length of the perpendicular of the given equilateral triangle is 13.85.
For more questions related to equilateral
https://brainly.com/question/2351368
#SPJ1
You are deciding between two cars with different engines and want the bigger
of the two. One engine displaces 350 cubic inches. The other displaces 5,500
cubic centimeters. Check all of the reasonable approaches to solving this
question.
Answers
The bigger engine is larger than the smaller one by 235.4724 cubic centimeters.
How is the bigger engine larger than other?We know that 1 inch=2.54 centimeters
Then 1 cubic inches-(2.54)^3 cubic centimeters
We have that:
⇒ 1 cubic inches=(2.54)3 = 16.3870 cubic centimeters
⇒350 cubic inches= 350 x 16.3870 = 5735.4724 cubic centimeters
Since, the other displaces 5,500 cubic centimeters and 5735.4724< 5500. The difference between them is:
= 5735.4724 - 5500
= 235.4724
Hence, the bigger engine larger than the smaller one by 235.4724 cubic centimeters.
Read more about Engine size
brainly.com/question/14439953
#SPJ1
Some students at Cook Middle School and Elm Middle School participated in a survey. They were asked which sports drink they prefer: Gym Juice or Energy Flow. The two-way table shows the results. What is the relative frequency of all students surveyed who go to Cook Middle School and prefer Energy Flow?
Answers
The relative frequency of the given students surveyed and prefer to go to Cook Middle School and Energy Flow is equal to 0.4 or 40%.
The relative frequency of all students surveyed who go to Cook Middle School and prefer Energy Flow
= (Number of students go to Cook Middle School and prefer Energy Flow) /( total number of students surveyed)
From the given table,
The number of students who go to Cook Middle School and prefer Energy Flow is equal to 20.
The total number of students surveyed is equal to 50.
The relative frequency of all students surveyed who go to Cook Middle School and prefer Energy Flow is,
= 20/50
= 0.4
Therefore, the relative frequency of all students surveyed going to the Cook Middle School and prefer Energy Flow is equal to 0.4 or 40%.
learn more about relative frequency here
brainly.com/question/20399450
#SPJ4
The above question is incomplete, the complete question is :
Some students at Cook Middle School and Elm Middle School participated in a survey. They were asked which sports drink they prefer: Gym Juice or Energy Flow. The two-way table shows the results.
Gym Juice Energy Flow Total
Cook 15 20 35
Elm 5 10 15
Total 20 30 50
What is the relative frequency of all students surveyed who go to Cook Middle School and prefer Energy Flow?
which of the following is a correct statement regarding the null hypothesis? the null hypothesis is sometimes called the alternative hypothesis. the null hypothesis is the one the researcher cares the most about. the null hypothesis claims the opposite of what the researcher believes. the null hypothesis is usually more accurate than the research hypothesis.
Answers
The correct statement regarding the null hypothesis is: the null hypothesis claims the opposite of what the researcher believes.
The null hypothesis is the claim that no relationship exists between two sets of data or variables being analyzed. The
null hypothesis is that any experimentally observed difference is due to chance alone, and an underlying causative
relationship does not exist, hence the term "null".
In research, the null hypothesis is a statement of no effect or no relationship between variables, while the alternative
hypothesis represents the effect or relationship the researcher is interested in demonstrating.
The purpose of statistical testing is to determine whether there is enough evidence to reject the null hypothesis in
favor of the alternative hypothesis.
for such more question on null hypothesis
https://brainly.com/question/25263462
#SPJ11
WILL MARK AS BRAINLEIST!!
Question in picture!!
Note: The graph above represents both functions “f” and “g” but is intentionally left unlabeled
Answers
Answer:
f(x) is the blue graph, g(x) is the red graph.
x^2 - 3x + 17 - (2x^2 - 3x + 1) = 16 - x^2
16 - x^2 = 0 when x = -4, 4
So the area between these two graphs is (using the TI-83 graphing calculator):
fnInt (16 - x^2, x, -4, 4) = 85 1/3
Rick is building a sandbox for his cousins in the shape of a parallelogram. When drawn on a coordinate plane, the sandbox has vertices at (-4,0), (-2,6), (4,0), and (2,-6). If every unit represents a foot, what area does the sandbox cover?
~a.) 24ft²
~b.) 36ft²
~c.) 48ft²
~d.) 64ft²
Answers
The area of the sandbox of parallelogram shape is approximately 22.47 square feet. Rounded to the nearest integer, the answer is (a) 24ft².
What is a parallelogram?A parallelogram is a quadrilateral with two pairs of parallel sides. Opposite sides of a parallelogram are equal in length and parallel to each other. Additionally, opposite angles of a parallelogram are congruent (i.e., have the same measure).
According to the given informationWe can choose any side of the parallelogram as the base, and the distance from that side to the opposite side as the height. Let's choose the side between (-4,0) and (-2,6) as the base. The length of this side is the distance between these two points:
√[(-2-(-4))² + (6-0)²] = √40 = 2√10
The height of the parallelogram is the distance between the line containing (-2,6) and (4,0) and the point (2,-6). We can find the equation of the line containing (-2,6) and (4,0) by finding the slope and y-intercept:
Slope: (0-6)/(4-(-2)) = -6/6 = -1
Y-intercept: y = mx + b -> 0 = (-1)(4) + b -> b = 4
Therefore, the equation of the line is y = -x + 4. We can find the distance between this line and the point (2,-6) by substituting x = 2 into the equation and finding the corresponding y-value:
y = -x + 4 = -2
The distance between the line and the point (2,-6) is the absolute value of the difference between the y-coordinate of the point and the y-coordinate of the line:
|(-6) - (-2)| = 4
Therefore, the height of the parallelogram is 4 feet.
The area of the parallelogram is then:
A = base x height = (2√10) x 4 = 8√10
Rationalizing the denominator, we get:
A = 8√10 x √10/√10 = 80/√10 = 80√10/10 = 8√10
Therefore, the area of the sandbox is approximately 22.47 square feet. Rounded to the nearest integer, the answer is (a) 24ft².
To know more about the parallelogram visit:
brainly.com/question/30577516
#SPJ1
at a booth at the school carnival in past years, they've found that 22% of students win a stuffed toy ($3.60), 16% of students win a jump rope ($1.20), and 6% of students win a t-shirt ($7.90). the remaining students do not win a prize. if 150 students play the game at the booth, how much money should the carnival committee expect to pay for prizes for that booth?: *
Answers
For a percentage data of students who play the different game and win the prize, the expected amount to pay for prizes for that booth by the carnival committee is equals to the $218.70.
We have a booth of school carnival in past years, The percentage of students win a stuffed toy = 22%
The percentage of students win a jump rope = 16%
The percentage of students win a t-shirt
= 6%
The winning amount for stuffed toy game = $ 3.60
The winning amount for jump rope game = $1.20
The winning amount for t-shirt game
= $7.90
The remaining students do not win a prize. Now, total number of students play the game at the booth = 150
So, number of students who win stuffed toy = 22% of 150 = 33
Number of students who win jump rope = 16% of 150 = 24
Number of students who win stuffed toy
= 6% of 150 = 9
For determining the expected pay using the simple multiplication formula. Total expected pay for prizes for that booth is equals to the sum of resultant of multiplcation of number of students who play a particular game into pay amount for that game. That is total excepted pay in dollars = 3.60 × 33 + 1.20 × 24 +7.90 × 6
= 218.7
Hence required value is $218.70.
For more information about percentage, visit:
https://brainly.com/question/843074
#SPJ4
a bank took a sample of 100 of its delinquent credit card accounts and found that the mean owed on these accounts was $2,130. it is known that the standard deviation for all delinquent credit card accounts at this bank is $578. (hint: first write out the values for n, , and ) 1. what is the margin of error for the sample mean at a 95% confidence level? hint: look at the notes given above to see how the margin of error is computed. 2. will the margin of error increase/decrease if 200 delinquent credit cards were sampled instead of 100? why? hint: look at the notes given above to see how the margin of error is computed and how the sample size n impacts its value.
Answers
Sampled 200 delinquent credit card accounts instead of 100, the margin of error would decrease.
Sampled 200 delinquent credit card accounts, the margin of error for the sample mean at a 95% confidence level would be $80.164.
Smaller than the margin of error we found earlier for a sample size of 100.
The margin of error for the sample means at a 95% confidence level, we need to use the formula:
[tex]Margin of error = z\times (standard deviation / square root of sample size)[/tex]
[tex]z\times[/tex] is the z-score for the 95% confidence level, which is 1.96.
So, plugging in the given values, we get:
[tex]Margin of error = 1.96 \times (578 / \sqrt 100)[/tex]
[tex]Margin of error = 1.96 \times 57.8[/tex]
Margin of error = 113.008
Therefore, the margin of error for the sample mean at a 95% confidence level is $113.008.
Repeated samples of 100 delinquent credit card accounts and computed the sample mean each time, we would expect the true population mean to be within $113.008 of our sample mean about 95% of the time.
The margin of error is inversely proportional to the square root of the sample size. So, as the sample size increases, the margin of error decreases.
To see this, let's plug in the new sample size into the margin of error formula:
[tex]Margin of error = 1.96 \times (578 / \sqrt 200)[/tex]
[tex]Margin of error = 1.96 \times 40.9[/tex]
Margin of error = 80.164
For similar questions on Margin
https://brainly.com/question/30404882
#SPJ11
A company is designing a new cylindrical water bottle. The volume of the bottle will be 150 cm^3. The height of the water bottle is 8.9 cm. What is the radius of the water bottle? Use 3.14 for π.
Answers
The radius of the water bottle which is in cylindrical shape is approximately 2.12 cm.
What is the cylindrical shape?A cylinder is a three-dimensional shape that consists of two congruent, parallel circular bases that are connected by a curved lateral surface. The lateral surface of the cylinder is formed by a rectangle that is wrapped around the circular bases.
A cylinder can be thought of as a circular prism, where the bases are circles and the lateral surface is curved. The height of a cylinder is the perpendicular distance between the two bases, and the radius is the distance from the center of the base to the edge of the circular base.
According to the given informationThe formula for the volume of a cylinder is V = πr^2h, where V is the volume, r is the radius, and h is the height. We can rearrange this formula to solve for the radius:
r = √(V/πh)
Substituting the given values, we have:
r = √(150/π(8.9))
r ≈ 2.12 cm (rounded to two decimal places)
Therefore, the radius of the water bottle is approximately 2.12 cm.
To know more about the Cylinder visit:
brainly.com/question/15891031
#SPJ1
select the correct answer. the probability of event a is x, and the probability of event b is y. if the two events are independent, which condition must be true?
Answers
For events A and B to be independent, the condition that must be true is:
P(A ∩ B) = x * y
The correct condition that must be true if events A and B are independent is:
P(A ∩ B) = P(A) x P(B).
where P(A) is the probability of event A, P(B) is the probability of event B, and P(A ∩ B) is the probability of both events A and B occurring together.
In other words, if events A and B are independent, then the probability of both events occurring together is equal to the product of their individual probabilities.
When two events A and B are independent, the following condition must be true:
P(A ∩ B) = P(A) * P(B)
In your case, the probability of event A is x, and the probability of event B is y.
Therefore, the correct answer is:
P(A ∩ B) = x*y
For similar question on condition.
https://brainly.com/question/10739947
#SPJ11
TRUE or FALSE:In the data analysis step, the idea is to learn how information currently flows and to pinpoint why it is not flowing properly.
Answers
The goal of the data analysis stage is to figure out how information is currently flowing and why it isn't flowing properly. The statement is True.
The basic purpose of data analysis is to obtain meaningful insights and information from data by examining it. While knowing how information progresses is an important part of this process, the ultimate goal is to get a better knowledge of the data itself, as well as any patterns or correlations that may exist within it.
The process of troubleshooting and problem-solving is more directly tied to determining why information is not flowing properly. This may entail examining the data to discover any abnormalities, mistakes, or inconsistencies that may be interfering with information flow. Once these concerns have been recognized, efforts may be made to fix them and enhance information flow.
Therefore, the statement is true, the goal of the data analysis stage is to figure out how information is currently flowing and why it isn't flowing properly.
Learn more about Data Analysis:
https://brainly.com/question/29214006
#SPJ4
TRUE. In the data analysis step, the focus is on examining and evaluating data to identify patterns, trends, and insights. The goal is to pinpoint any issues or inefficiencies in the way information flows and to determine the root cause of these problems.
By analyzing the data, organizations can gain a better understanding of their processes and identify areas for improvement.
In the data analysis step, the goal is to examine and understand the current flow of information. This involves analyzing the data to identify patterns, trends, and any potential issues. By pinpointing the reasons why the information is not flowing properly, you can then work towards implementing solutions to improve the efficiency and effectiveness of the data management process.
To learn more about Analysis - brainly.com/question/29926939
#SPJ11
Copy
State
This
prior
any r
perm
Man
avv
ttr
opy
om
and
av
Marven and three friends are renting a car for a trip. Rental prices are
shown in the table.
Item
PART B
Small car rental fee
-seats 4 passengers
Full-size car rental fee
-seats 4 passengers
Insurance
Price
465=25x
$39/day
$49/day
$21/day
25
(X=18.6
-198
018.6
1465
LIS
If they still use the coupon, how many days could they rent the small car
with insurance if they have $465 to spend?
Answers
Since they can't rent for a fraction of a day, the maximum number of days they can rent the small car with insurance is 10 days.
Insurance calculation.
The total cost of renting a small car with insurance is:
$465 = $25x + $21x
Simplifying and solving for x, we get:
$465 = $46x
x = 10.11
Since they can't rent for a fraction of a day, the maximum number of days they can rent the small car with insurance is 10 days.
Learn more about insurance below.
https://brainly.com/question/25221455
#SPJ1
in a standard additions method workup what information from the linear regression is most closely related to the unknown concentration? (used to determine it)
Answers
In a standard additions method workup the information from the linear regression that is most closely related to the unknown concentration is this: the intercept of the linear regression line.
What information is closest to the unknown concentration?In the standard additions method workup, the information that is most closely related to the unknown concentration is the intercept of the linear regression line.
The reason why this is the case is that the intercept represents the y-value of the regression line where the line crosses the y-axis. This y-axis is the value of the dependent variable when the independent variable or concentration is zero. So, by solving for the intercept, we can determine the concentration of the unknown sample.
Learn more about linear regression here:
https://brainly.com/question/25987747
#SPJ1
the percentage of the original area of wetlands currently left in the united states is approximately: question 44 options: 10%. 25%. 50%. 65%. 75%.
Answers
The percentage of the original area of wetlands currently left in the United States is approximately 50%. So, the correct
option is 50% (option 3).
Percentages are a way of expressing a proportion or a fraction as a part of 100. It is denoted by the symbol "%".
According to the United States Environmental Protection Agency (EPA), it is estimated that about 50% of the original
wetlands in the contiguous United States have been lost since the 1600s due to human activities such as agriculture,
development, and urbanization. Therefore, the correct answer to the question is 50%.
for such more questions on percentages
https://brainly.com/question/24877689
#SPJ11
The percentage of the original area of wetlands currently left in the United States is approximately 50%.
Wetlands are regions of land where the soil is continually or intermittently soaked with water. Wetlands have a particular hydrology, soil, and vegetation mix that results in specialised ecosystems that offer a variety of ecological functions.
There are many different types of habitats where wetlands can be found, such as coastal locations, interior regions, and high-altitude mountain regions. They come in a variety of shapes, such as marshes, swamps, bogs, fens, and estuaries, and can be freshwater, brackish, or saline.
Wetlands are significant for several reasons. For species, such as migrating birds, amphibians, and fish, they offer crucial habitats. They also aid in removing contaminants from water, lessen the effects of flooding, and give people access to recreational activities. Wetlands are crucial for carbon sequestration as well.
Based on the information provided, the question is asking for the approximate percentage of the original area of wetlands currently left in the United States. The answer is approximately 50%.
Learn more about wetlands here:
https://brainly.com/question/30010590
#SPJ11
how to solve this equetion. a scientist used 786 millileters
Answers
The scientist used 0.786 liters of the liquid for the experiment.
Unit conversion:Unit conversion is the process of converting a quantity expressed in one unit of measurement to an equivalent quantity expressed in a different unit of measurement.
To convert between different units of measurement, we need to use conversion factors, which relate to the two units.
In this case, the conversion factor is 1 liter = 1000 milliliters, which allows us to convert from milliliters to liters by dividing by 1000.
Here we have
A scientist used 786 millimeters
To convert milliliters to liters, we need to divide by 1000 since there are 1000 milliliters in one liter.
So, to convert 786 milliliters to liters, we divide by 1000:
786 milliliters ÷ 1000 = 0.786 liters
Therefore,
The scientist used 0.786 liters of the liquid for the experiment.
Learn more about Unit conversion at
https://brainly.com/question/19420601
#SPJ1
Complete Question:
A scientist used 786 milliliters of a liquid for an experiment. How many liters of the liquid did the scientist use for this experiment?
true or false? the rule of thumb for estimating the time of completion is 1.5 times what you originally think it will be.
Answers
Given statement: The rule of thumb for estimating the time of completion is 1.5 times what you originally think it will be.
Given statement is True.
The reason for this rule of thumb is that tasks often take longer than initially estimated due to unforeseen challenges, dependencies, and other factors that can cause delays.
By estimating the time of completion as 1.5 times the original estimate, you are accounting for these potential delays and allowing for a more realistic timeline.
This rule of thumb is not a hard and fast rule, and there will be cases where tasks take less or more time than 1.5 times the original estimate. However, it can be a helpful guideline for project planning and resource allocation, as it helps to ensure that sufficient time and resources are allocated to complete tasks within a realistic timeframe.
For similar question on estimating.
https://brainly.com/question/597381
#SPJ11
1. The area of a rectangle can be represented by a
quadratic function. You are given a rectangle with a length
that is 3 inches more than four times the width, w. Choose
all the answers that give the area as a function of the
width
a) A(w)=w(4+3w)
b) A(w)=w(3+4w)
c) A(w)=4w+3w²
d) A(w)=4w²+3w
-7
Answers
The expression that gives the area as a function of the width is 4w²+3w.( option B)
What is area of a rectangle?The area of a shape is the space occupied by the boundary of a plane figures like circles, rectangles, and triangles.
The area of a rectangle is expressed as ;
A = l×w, where l is the length and w is the width.
Since the length is 3 inches more than four times the width, then;
l = 3+4w
Representing 3+w for l in the area formula, then we have;
A = (3+4w)(w)
A = 4w²+3w
therefore the expression that represents the area is 4w²+3w
learn more about area of rectangle from
https://brainly.com/question/2607596
#SPJ1
for a certain type of hay fever, medicine h has a 30% probability of working. in which distributions does the variable x have a binomial distribution? select each correct answer.
Answers
The distribution in which variable x has binomial distribution are as follow,
Option A) When the medicine is tried with two patients, X is the number of patients for whom the medicine worked.
Option D) When the medicine is tried with six patients, X is the number of patients for whom the medicine worked.
When the medicine is tried with two patients, X is the number of patients for whom the medicine worked.
This variable X follows a binomial distribution .
Because there are two independent trials two patients.
With a constant probability of success 30%.
And the outcome of one trial doesn't affect the outcome of the other.
When the medicine is tried with six patients, X is the number of patients for whom the medicine does not work.
This variable X does not follow a binomial distribution.
Because the probability of success is not constant it's the complement of 30%, which is 70%.
Also, the outcome of one trial affects the outcome of the other trials.
As there are only six patients .
Number of patients for whom medicine does not work depends on number of patients for whom it worked.
When the medicine is tried with six patients, X is the number of patients for whom the medicine worked.
This variable X follows a binomial distribution.
Because there are six independent trials six patients with a constant probability of success (30%) .
The outcome of one trial doesn't affect the outcome of the other.
When the medicine is tried with two patients, X is the number of doses each patient needs to take.
This variable X does not follow a binomial distribution.
Because it's not a count of successes out of a fixed number of independent trials.
But rather a continuous variable that can take any non-negative value.
Learn more about binomial distribution here
brainly.com/question/12702509
#SPJ4
The above question is incomplete, the complete question is:
For a certain type of hay fever, Medicine H has a 30% probability of working.
In which distributions does the variable X have a binomial distribution?
Select EACH correct answer.
A. When the medicine is tried with two patients, X is the number of patients for whom the medicine worked.
B. When the medicine is tried with six patients, X is the number of patients for whom the medicine does not work.
C. When the medicine is tried with six patients, X is the number of patients for whom the medicine worked.
D. When the medicine is tried with two patients, X is the number of doses each patient needs to take.
From the top of a 120-foot-high tower, an air traffic controller observes an airplane on the runway at an angle of depression of 19°. How far from the base of the tower is the airplane? Round to the nearest tenth.
1. 126.9 ft
2. 368.6 ft
3. 41.3 ft
4. 348.5 ft
Answers
The distance of the base of the tower and the airplane is 348.5 ft, and the right option is 4. 348.5 ft.
What is distance?Distance is the length between two points.
To calculate the distance of the base of the tower and the airplane, we use the formula below.
Formula:
Tan∅ = Opposite(O)/Adjacent(A)Where:
∅ = Angle of depression of the airplaneFrom the diagram,
Given:
Opposite = 120 ft∅ = 19°SUbstitute these values into equation 1 and solve for A
tan19° = 120/AA = 120/tan19°A = 348.5 ftHence, the right option is 4. 348.5 ft.
Learn more about Distance here: https://brainly.com/question/26046491
#SPJ1
I’ve been trying to solve this for a long time now and I just keep getting it wrong, if anyone could assists me that would be appreciated! :)
Answers
The distance between the two points can be found to be, and the number that goes beneath the radical symbol is 80.
How to find the distance ?To find the distance between two points in a plane, you can use the distance formula derived from the Pythagorean theorem. The distance formula is:
d = √[(x₂ - x₁)² + (y₂ - y₁)²]
where (x₁, y₁) and (x₂, y₂) are the coordinates of the two points.
In this case, the coordinates of the two points are (-4, 1) and (4, 5). So, x₁ = -4, y₁ = 1, x₂ = 4, and y₂ = 5.
Now, apply the distance formula:
d = √[(4 - (-4))² + (5 - 1)²]
d = √[(8)² + (4)²]
d = √(64 + 16)
d = √80
Find out more on distance at https://brainly.com/question/7243416
#SPJ1
compute the residuals. (round your answers to two decimal places.) xi yi residuals 6 6 11 7 15 12 18 20 20 30 (c) develop a plot of the residuals against the independent variable x. do the assumptions about the error terms seem to be satisfied?
Answers
The estimated regression equation for the given data is y = -30.7 + 3.409x
To develop an estimated regression equation for the given data, we need to use the method of least squares.
The formula for the slope of the regression line is given by:
b = ∑(xi - x)(yi - y) / ∑(xi - x)²
where xi and yi are the individual values of the two variables, x and y are their respective means.
The formula for the intercept of the regression line is given by:
a = y - b × x
where a is the intercept and b is the slope.
Using the given data, we can calculate the values of x, y, b, and a as follows
x = (6 + 11 + 15 + 18 + 20) / 5 = 14
y = (7 + 9 + 12 + 21 + 30) / 5 = 15.8
∑(xi - x)(yi - y) = (6 - 14)(7 - 15.8) + (11 - 14)(9 - 15.8) + (15 - 14)(12 - 15.8) + (18 - 14)(21 - 15.8) + (20 - 14)(30 - 15.8) = 306.8
∑(xi - x)² = (6 - 14)² + (11 - 14)² + (15 - 14)² + (18 - 14)² + (20 - 14)² = 90
b = ∑(xi - x)(yi - y) / ∑(xi - x)² = 306.8 / 90 = 3.409
a = y - b × x = 15.8 - 3.409 × 14 = -30.7
Learn more about regression equation here
brainly.com/question/14184702
#SPJ4
The given question is incomplete, the complete question is:
Given are data for two variables, x and y. Develop an estimated regression equation for these data.
1. 12s + 4t
2. 46rs + 10x
3. 12q + 14x
4. 10x + 10y
5. 17rs + 32x
6. 5x + 7y - 12z
7. 36ab + 70m
8. 3r + 19a + 10m
9. 7k + 16m
10. 8r + 5s
11. 9h + 120m
12. 12k + m
13. 7g + 15h + w
14. 4c - 8d + 12f
15. 6t + 17r - 35j
Answers
Here are the given expressions and their respective variables and coefficients:
The Variables and Coefficients12s + 4t | Variables: s, t | Coefficients: 12, 4
46rs + 10x | Variables: r, s, x | Coefficients: 46, 10
12q + 14x | Variables: q, x | Coefficients: 12, 14
10x + 10y | Variables: x, y | Coefficients: 10, 10
17rs + 32x | Variables: r, s, x | Coefficients: 17, 32
5x + 7y - 12z | Variables: x, y, z | Coefficients: 5, 7, -12
36ab + 70m | Variables: a, b, m | Coefficients: 36, 70
3r + 19a + 10m | Variables: r, a, m | Coefficients: 3, 19, 10
7k + 16m | Variables: k, m | Coefficients: 7, 16
8r + 5s | Variables: r, s | Coefficients: 8, 5
9h + 120m | Variables: h, m | Coefficients: 9, 120
12k + m | Variables: k, m | Coefficients: 12, 1
7g + 15h + w | Variables: g, h, w | Coefficients: 7, 15, 1
4c - 8d + 12f | Variables: c, d, f | Coefficients: 4, -8, 12
6t + 17r - 35j | Variables: t, r, j | Coefficients: 6, 17, -35
Read more about Coefficients here:
https://brainly.com/question/1038771
#SPJ1
according to the centers for disease control and prevention, 60% of all american adults ages 18 to 24 currently drink alcohol. is the proportion of california college students who currently drink alcohol different from the proportion nationwide? a survey of 450 california college students indicates that 66% curre quizlert
Answers
the proportion of California college students who currently drink alcohol different from the proportion nationwide p0 = 0.60 (nationwide proportion from CDC)
Information provided; we can determine if the proportion of California college students who currently drink alcohol is different from the proportion nationwide by conducting a hypothesis test. Here are the steps:
The null hypothesis (H0) and alternative hypothesis (H1):
H0: The proportion of California college students who drink alcohol is the same as the nationwide proportion.
(p = 0.60).
H1: The proportion of California college students who drink alcohol is different from the nationwide proportion.
(p ≠ 0.60).
The sample proportion (p-hat), sample size (n), and the population proportion (p0):
p-hat = 0.66 (66% of the 450 California college students surveyed)
n = 450 (sample size)
p0 = 0.60 (nationwide proportion from CDC)
The test statistic (z) using the following formula:
[tex]z = (p-hat - p0) / \sqrt((p0 \times (1 - p0)) / n)[/tex]
A standard normal distribution table or calculator to find the p-value associated with the test statistic.
Compare the p-value to a predetermined significance level (α), usually set at 0.05.
- If the p-value is less than α, reject the null hypothesis (H0), suggesting that the proportion of California college students who drink alcohol is different from the nationwide proportion.
- If the p-value is greater than α, fail to reject the null hypothesis (H0), indicating that there is not enough evidence to suggest a difference between the two proportions.
Determine if the proportion of California college students who drink alcohol is significantly different from the nationwide proportion.
For similar questions on proportion
https://brainly.com/question/19994681
#SPJ11
Which ratio is proportional to 80:60?
16:15
16:12
18:15
18:12
Pls answer quickly
Answers
Answer:
To determine which ratio is proportional to 80:60, we need to simplify the ratio by dividing both terms by their greatest common factor. In this case, the greatest common factor of 80 and 60 is 20, so:
80/20 = 4
60/20 = 3
Therefore, the simplified ratio is 4:3.
Now we can compare this ratio to the given options to see which one is proportional to 4:3:
16:15 is not proportional
16:12 is proportional (since 16/4 = 4 and 12/3 = 4)
18:15 is not proportional
18:12 is proportional (since 18/3 = 6 and 12/2 = 6)
Therefore, the ratio that is proportional to 80:60 is 16:12.
A $2 coin with a diameter of 25. 75 mm. How many turns does such a piece make if you roll it on the edge for 1. 34 m?
Answers
The coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
How to find the number of turns the coin makes?The circumference of the coin can be calculated as follows to determine the number of turns it makes:
C = πd
where C is the circumference, d is the diameter, and π is the mathematical constant pi (approximately equal to 3.14159).
So, for the given $2 coin with a diameter of 25.75 mm, the circumference is:
C = πd = 3.14159 x 25.75 mm ≈ 80.926 mm
Divide the distance traveled by the coin's circumference to determine the number of turns it makes when rolled on its edge for 1.34 meter:
Number of turns = distance traveled / circumference of the coin
Number of turns = 1.34 m / 0.080926 m
Number of turns ≈ 16.53
Therefore, the coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
know more about circumference visit :
https://brainly.com/question/28757341
#SPJ1
a work system has five continuous stations that have process times of 5, 8, 4, 7, and 8 min/unit respectively. what is the process time of the system?
Answers
The process time of the system is 32 min/unit.
Can someone help me asap? It’s due tomorrow. I will give brainiest if it’s correct.
A. 23
B. 61
C. 37
D. 14
Answers
Answer: the answer is A. 14.
Step-by-step explanation: In each trial of the reenactment, Scott chooses one card from the stack and records its digit. Based on the given data, a digit of or 1 speaks to a objective scored, and a digit of 2 through 9 speaks to a missed endeavor.
Out of the 5 endeavors per amusement, on the off chance that Scott scores precisely 2 objectives, it implies he missed 3 endeavors. Subsequently, the likelihood of this occasion can be calculated as:
P(exactly 2 objectives) = (0.2)²(0.8)³ = 0.008192
This likelihood can be utilized to discover the anticipated number of diversions in which Scott scores precisely 2 objectives, by duplicating it by the overall number of diversions reenacted:
Anticipated number of recreations = P(exactly 2 objectives) × Add up to number of recreations = 0.008192 × 84 ≈ 0.68
Adjusting to the closest entire number, we get that Scott is anticipated to score precisely 2 objectives in 1 diversion out of the 84 recreated diversions.
Solving systems by eliminations; finding the coeficients
please write all the problems down, 10 points for each problem, and Brainliest
Answers
Therefore, the solution is equation (x, y) = (52/7, -10/7).
To solve the system of equations by elimination, we need to eliminate one of the variables. We can do this by multiplying one or both equations by a constant to create opposite coefficients for one of the variables. Then, we can add or subtract the equations to eliminate that variable and solve for the other variable. Here's how to solve the given system of equations:
Multiply the first equation by 3 and the second equation by 2 to create opposite coefficients for y:
[tex]3(x - 2y = 12) - > 3x - 6y = 36[/tex]
[tex]2(-5x + 3y = -44) - > -10x + 6y = -88[/tex]
Add the equations to eliminate y:
[tex]3x - 6y + (-10x + 6y) = 36 + (-88)[/tex]
[tex]-7x = -52[/tex]
Solve for x by dividing both sides by -7:
[tex]x = 52/7[/tex]
Substitute x = 52/7 into either equation to solve for y. Using the first equation:
[tex]52/7 - 2y = 12[/tex]
[tex]-2y = 12 - 52/7[/tex]
[tex]-2y = 72/7 - 52/7[/tex]
[tex]-2y = 20/7[/tex]
[tex]y = -(10/7)[/tex]
Check the solution by substituting the values of x and y into both equations:
[tex]x - 2y = 12 - > 52/7 - 2(-10/7) = 12 (true)[/tex]
[tex]-5x + 3y = -44 - > -5(52/7) + 3(-10/7) = -44 (true)[/tex]
Therefore, the solution is (x, y) = (52/7, -10/7).
To know more about equation visit:
https://brainly.com/question/10413253
#SPJ1