Answers
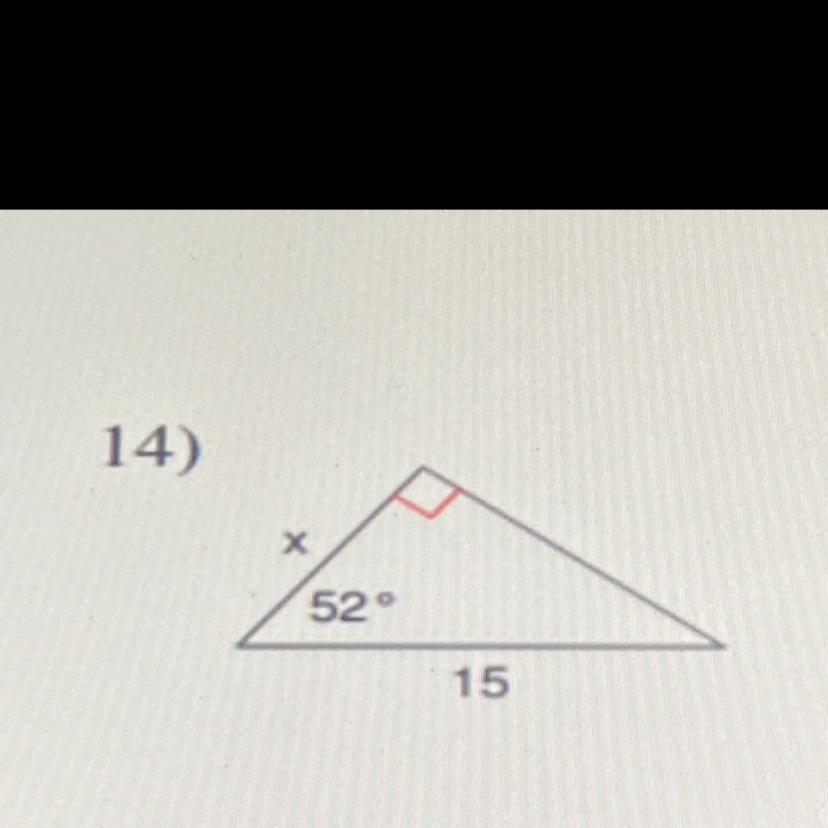
The measure of the unknown side from the given triangle is 14.48.
Solving trigonometry identityThe given triangle is a right triangle with the following sides;
Hypotenuse = 15
Adjacent = x
Acute angle = 52 degrees
We are to determine the measure of the unknown side using trigonometry identity
Cos 15 = Adjacent/Hypotenuse
Cos 15 = x/15
x = 15cos15
x = 15(0.9659)
x = 14.48
Hence the measure of the unknown side is 14.48
Learn more on trigonometry identity here: https://brainly.com/question/24496175
#SPJ1
Related Questions
The table shows the weekly income of 20 randomly selected full-time students. If the student did not work, a zero was entered (a) Check the data set for outliers (b) Draw a histogram of the data (c) Provide an explanation for any outliers
Answers
a) Any value outside of Q1 - 1.5(IQR) and Q3 + 1.5(IQR) can be considered a potential outlier.
b) This will give us a visual representation of the distribution of income among the full-time students.
c) It is important to analyze outliers carefully to ensure that they are not artificially skewing the results of our analysis.
(a) To check for outliers in the data set, we can use the box-and-whisker plot or the z-score method. However, since we do not have the exact data, we cannot use these methods. One way to identify potential outliers is to calculate the quartiles (Q1, Q2, and Q3) and the interquartile range (IQR).
(b) To draw a histogram of the data, we can use the frequency distribution table given in the question. The x-axis should represent the income ranges (e.g. $0-$100, $100-$200, etc.) and the y-axis should represent the frequency (i.e. the number of students who earned income within each range).
(c) If there are any outliers in the data set, we need to investigate them further to determine the reason for their unusual values. Possible reasons for outliers could be data entry errors, extreme values due to high- or low-income jobs, or unique situations such as unexpected windfalls or emergencies.
To learn more about frequency distribution visit;
https://brainly.com/question/14926605
#SPJ11
Point A = (5,4). If you rotated A 90 degrees about the point (2,-1), what would be the coordinates of A'?
Answers
Point A = (5,4). If you rotated A 90 degrees about the point (2,-1), the coordinates of A' is (-1,2).
Describe Rotation?Rotation is the process of rotating an object or a point around a fixed point or axis. In mathematics, rotation refers to a transformation that preserves the size and shape of an object while changing its orientation. It is a basic geometric transformation that is used in various fields, including mathematics, physics, engineering, and computer graphics.
In a two-dimensional space, a rotation is typically described by an angle of rotation and a fixed point, which is known as the center of rotation. The angle of rotation represents the amount by which the object is rotated, while the center of rotation is the point around which the object is rotated. In a three-dimensional space, a rotation is described by an axis of rotation and an angle of rotation.
To rotate point A 90 degrees counterclockwise about the point (2,-1), we can use the following formula:
A' = (x', y') = (a + (x - a) cosθ - (y - b) sinθ, b + (x - a) sinθ + (y - b) cosθ)
where (a,b) is the center of rotation and θ is the angle of rotation (90 degrees in this case).
Substituting the given values, we get:
a = 2, b = -1, x = 5, y = 4, θ = 90 degrees
x' = 2 + (5 - 2) cos(90) - (4 + 1) sin(90) = 2 - 3 = -1
y' = -1 + (5 - 2) sin(90) + (4 + 1) cos(90) = -1 + 3 = 2
Therefore, the coordinates of A' are (-1, 2).
To know more about coordinates visit:
https://brainly.com/question/18596983
#SPJ9
Mr. Frost worked 37 hours last week. He was paid $17 per hour. How much money did he make last week?
Answers
Answer:
$481
Step-by-step explanation:
37×$17=$481
he made $481
A ( x + 3 ) < 5x + 15 - x
find the value for a for which the solution of the inequality is all real numbers
Answers
The value of a for which the solution of the inequality is all real numbers is a = 5.
We have to first simplify the inequality:
A(x + 3) < 5x + 15 - x
Ax + 3A < 4x + 15
Ax - 4x < 15 - 3A
Simplifying further:
x(A - 4) < 15 - 3A
Now, we need the inequality to hold for all real values of x. This means that the coefficient of x, (A - 4), must have a fixed sign, and that the right-hand side, 15 - 3A, must be unbounded.
For the coefficient of x to have a fixed sign, we need either A - 4 < 0 or A - 4 > 0. This means that A must be less than 4 or greater than 4.
For the right-hand side to be unbounded, we need 15 - 3A to be equal to positive or negative infinity. Since 15 - 3A is a linear function of A, this only occurs when A = 5.
So, the solution to the inequality for all real numbers is:
if A < 4, then the solution is x < (15 - 3A) / (4 - A)
if A > 5, then the solution is x > (15 - 3A) / (4 - A)
if A = 5, then the solution is all real numbers.
To know more about inequality
https://brainly.com/question/30231190
#SPJ4
the cylinder with the height of 4 M has a volume of 2,827.43 cubic meters find the length of the diameter
Answers
[tex]\textit{volume of a cylinder}\\\\ V=\pi r^2 h~~ \begin{cases} r=radius\\ h=height\\[-0.5em] \hrulefill\\ V=2827.43\\ h=4 \end{cases}\implies 2827.43=\pi r^2(4)\implies \cfrac{2827.43}{4\pi }=r^2 \\\\\\ \sqrt{\cfrac{2827.43}{4\pi }}=r\hspace{5em}\stackrel{\textit{twice that is the \underline{diameter}}}{2\sqrt{\cfrac{2827.43}{4\pi }}} ~~ \approx ~~ \text{\LARGE 30}[/tex]
What are the amplitude, period, and phase shift of the given function ft=-1/2(4t-2pi)
Answers
Answer:
The amplitude is 1/2, the period is 2π/4 = π/2, and the phase shift is π/2.
Step-by-step explanation:
The given function is:
f(t) = -1/2(4t - 2π)
We can rewrite this function in the form:
f(t) = A cos(B(t - C)) + D
where A is the amplitude, B is the period, C is the phase shift, and D is the vertical shift.
Comparing this with the given function, we can see that:
A = 1/2
B = 4
C = π/2
D = 0
Therefore, the amplitude is 1/2, the period is 2π/4 = π/2, and the phase shift is π/2.
Note that the negative sign in front of the function does not affect the amplitude, period, or phase shift. It simply reflects the function across the x-axis.
If the annual interest rate was 8%,
a.
How would you calculate the monthly interest rate?
Answers
The monthly interest rate is the annual interest rate divided by 12
Calculating the monthly interest rate?To calculate the monthly interest rate, we need to divide the annual interest rate by 12 (since there are 12 months in a year).
So if the annual interest rate is 8%, the monthly interest rate can be calculated as:
Monthly interest rate = Annual interest rate / 12
Monthly interest rate = 8% / 12
Monthly interest rate = 0.6667%
Therefore, the monthly interest rate would be 0.6667%.
Read more about interest at
https://brainly.com/question/24924853
#SPJ1
Evaluation researchers encounter more logistical problems than other researchers because evaluation researchA. occurs in the context of real life.B. takes longer.C. is more costly.D. has more measurement problems.E. examines more variables.
Answers
The answer is A. Evaluation researchers encounter more logistical problems than other researchers because evaluation research occurs in the context of real life.
Evaluation research often takes place in real-world settings, which can present logistical challenges such as accessing participants, coordinating schedules, and dealing with unexpected events. Additionally, evaluation research often involves multiple stakeholders and requires collaboration and communication among various groups, which can further complicate logistical issues. While evaluation research may also involve longer timelines, higher costs, measurement problems, and examination of multiple variables, these factors do not necessarily contribute to greater logistical challenges.
This means that evaluation researchers have to navigate complex, real-world situations, adapt to unforeseen challenges, and work with various stakeholders, making the research process more logistically challenging compared to controlled laboratory settings or theoretical research.
to learn more about theoretical research. click here:
https://brainly.com/question/29220441
#SPJ11
Evaluation research is a type of research that focuses on assessing the effectiveness, efficiency, and impact of programs, policies, or interventions in real-life settings.
The correct answer is A. occurs in the context of real life.
This often involves evaluating the outcomes and impacts of interventions in complex and dynamic environments, such as organizations, communities, or systems. As a result, evaluation researchers may encounter more logistical problems compared to other types of researchers because they need to navigate real-life contexts, deal with multiple stakeholders, collect data from diverse sources, and address issues such as ethics, confidentiality, and validity in the evaluation process. Logistical problems may include challenges related to data collection, measurement, sample selection, data quality, and managing time and resources.
Learn more about “ Logistical problems “ visit here;
https://brainly.com/question/31087596
#SPJ4
MODELING REAL LIFE The volume of the largest of the six pyramids constructed by the Norte Chico people in Caral, Peru, is about 4,500,000 cubic feet. What is the height of the pyramid? A pyramid with the height h feet. Length of 8 h minus 30 feet. Width of 8 h plus 20 feet. Height: ft
Answers
The height of the pyramid whose volume is already given would be = 1,440,000 ft
How to calculate the height of the given pyramid?To calculate the height of the pyramid, the formula of the Volume of the pyramid should be used.
Volume = 1/3lwh
where l = base length = 8h-30 ft= 3.75 ft
w = base width= 8h+20 ft = -2.5 ft
h = h ft
The volume of the pyramid = 4,500,000 cubic feet
4,500,000 = 1/3 × (3.75)(-2.5)h
Make h the subject of formula;
h = 4500000×3/3.75×(-2.5)
h = 13500000/9.375
h = 1,440,000 ft.
Learn more about pyramid here:
https://brainly.com/question/30517561
#SPJ1
Carla looks from a height of 1515 yards at the top of her apartment building. She lines up the top of a flagpole with the curb of a street 2020 yards away. If the flagpole is 1212 yards from the apartment building, how tall is the flagpole?
Answers
Answer: 4545 yards
Step-by-step explanation:
We can use similar triangles to solve this problem. Let's represent the height of the flagpole with the variable "x".
Using the triangle formed by Carla's line of sight, the height of the apartment building, and the top of the flagpole, we can set up the following proportion:
x / (x + 1515) = 15 / 20
Simplifying this proportion, we get:
4x = 3(x + 1515)
4x = 3x + 4545
x = 4545
Therefore, the height of the flagpole is 4545 yards.
Simplify these expressions
5×x
6×x×y
2×x×3×y
Answers
Answer:
5x
6xy
2x3y
hope it's helpful
the graph below displays the amount of time to the nearest hour spent on homework per week for a sample of students. which measures of center and variability would be most appropriate to describe the given distribution?
Answers
The measures of center and variability that would be most appropriate to describe the given distribution is D) Median and IQR.
What is median and IQR?The middle value in a set of data is represented by the median, a measure of central tendency. It is the value that, when a dataset's values are ranked from lowest to highest, distinguishes the lower from the upper half of the dataset.
The middle 50% of a dataset's interquartile range (IQR) is a measure of variability that captures this dispersion. It is the difference between the data's first (Q1) and third (Q3) quartiles. The number that divides the lowest 25% of the data from the remaining data is known as the first quartile, and the value that separates the highest 25% of the data from the remaining data is known as the third quartile.
Learn more about median here:
https://brainly.com/question/28060453
#SPJ1
The complete question is:
a report claims that the proportion of all adults who are vegetarians is 0.12. believing this claimed value is incorrect, a researcher surveys a large random sample of 1,000 adults and finds that 140 of the adults in the sample are vegetarians. what will the test statistic be equal to in this example? as you are engaging in calculations, try not to do a lot of rounding until you get to the very end, and choose the answer below that is closest to what you calculate. a. 2.5 b. 1.4 c. 1.9 d. 0.3 d. less than 0.1
Answers
The correct answer is (c) 1.9
How to calculate the test statistic?To calculate the test statistic in this example, we can use the formula for a z-test for proportions:
[tex]z = (p - P) / \sqrt{[P(1-P) / n][/tex]
where:
p is the sample proportion of vegetarians (140/1000 = 0.14)
P is the hypothesized population proportion of vegetarians (0.12)
n is the sample size (1000)
Substituting these values into the formula, we get:
[tex]z = (0.14 - 0.12) / \sqrt{[0.12(1-0.12) / 1000][/tex]
z = 0.02 / 0.0110
z = 1.818 (rounded to three decimal places)
Therefore, the test statistic in this example will be approximately equal to 1.818. The answer closest to this value is (c) 1.9
Learn more about test statistic
brainly.com/question/14128303
#SPJ11
<
1. Decide if each quadrilateral is a paranciogram. Explain
1 Pt
105
DOOOO
B
A
75
DE
1 Pt
OO
A B
4/7 -
11
65°
E
1 Pt.
For what value of x must the quadrilateral be a parallelogram?
A
O
B
с D E
A. Yes the quadrialateral is a parallelogram, because consecutive angle are supplementary.
B. Yes the quadrialateral is a parallelogram, because one pair of opposites sides is both
parallel and congruent
C. Yes the quadrialateral is a parallelogram, because opposite angles are congruent.
D. Yes the quadrialateral is a parallelogram, because diagonals bisect each other.
E. No we do not have enough information to prove this is a parallelogram.
IF YOU CAN HELP WITH SCHOOL FOR $ PLEASE ASK FOR MY CONTACT IN COMMENTS
Answers
For all given Quadrilaterals none has enough information provided in the problem to definitively say - if they are a parallelogram.Hence, option E is correct for all.
How to determine if Quadrilateral is a parallelogram?If a quadrilateral is a parallelogram, it satisfies the following properties:
Opposite sides are parallel.Opposite sides are equal in length.Opposite angles are equal.Diagonals bisect each other.It is important to note that in order to definitively conclude that a quadrilateral is a parallelogram, all four properties must be satisfied. If only one or some of the properties are met, it does not necessarily guarantee that the quadrilateral is a parallelogram.
Figure 1-: Adjacent angles are 105 and 75 degrees, which satify the condition of opposite angles being equal but except this no other information is provided, Hence, we don't have enough information to say figure 1 is a parallelogram.
Figure 2-: Diagonals bisect each other and make angle 65 degree with each other. Given that Diagonal 1 bisects Diagonal 2 and the opposite sides of the quadrilateral are equal, by using SAS criterion, the congruency of triangles formed by the diagonals can be derived to say that the opposite angles of the quadrilateral are also equal . However, we still need more information about parallelism of sides to definitively say given quadrilateral is a parallelogram.
Figure 3-: One pair of opposite side is equal in length ,while other pair of line is parallel to each other.This information is insufficient to determine if given quadrilateral is a parallelogram.
Learn more about parallelogram here:
https://brainly.com/question/29147156
#SPJ1
how many intervals (or 'bins' or 'classes') should be chosen when creating a histogram? question 1 options: most often, about 8-10. eleven. it can vary - it really depends on the distribution of the variable. a minimum of 5.
Answers
"It can vary - it really depends on the distribution of the variable."
The number of intervals, or bins, to choose when creating a histogram can vary depending on the distribution of the variable.
Most often, about 8-10 intervals are used, but there is no set rule. It is generally recommended to have at least 5 intervals, but if the data is highly skewed or has outliers, more intervals may be needed to accurately represent the distribution.
Ultimately, the goal is to choose a number of intervals that provides a clear visual representation of the data without oversimplifying or overcomplicating the histogram.
The number of intervals or bins to be chosen when creating a histogram can vary and it really depends on the distribution of the variable.
While most often, about 8-10 bins are used, there is no hard and fast rule for the number of bins to be used in a histogram.
In general, the number of bins should be large enough to display the shape of the distribution clearly, but not so large that it obscures important features of the distribution or leads to overfitting.
A minimum of 5 bins is recommended to display the basic shape of the distribution, but more bins may be necessary for complex or multi-modal distributions.
Depending on the distribution of the variable, a histogram's number of intervals or bins can be altered.
There is no established guideline, however 8–10 intervals are typically utilized.
A minimum of five intervals are often advised, however if the data is extremely skewed or contains outliers, more intervals could be required to correctly depict the distribution.
For similar questions on variable.
https://brainly.com/question/27894163
#SPJ11
Find the value of the indicated trigonometry ratio cos in right tringle with side of 6,6*squort 2, 6*squort 3
Answers
Answer:√2/2
Step-by-step explanation:
Let's label the sides of the right triangle as follows:
The side adjacent to the angle θ (cosine is adjacent/hypotenuse): 6
The hypotenuse (the longest side): 6√2
The side opposite to the angle θ (sine is opposite/hypotenuse): 6√3
Using the Pythagorean theorem, we can find the length of the missing side:
a² + b² = c²
6² + (6√3)² = (6√2)²
36 + 108 = 72
144 = 72
√144 = √72
12 = 6√2
Now that we know the length of all three sides, we can use the cosine ratio to find the value of cos(θ):
cos(θ) = adjacent/hypotenuse = 6/6√2 = √2/2
Therefore, the value of cos(θ) in the right triangle with sides of 6, 6√2, and 6√3 is √2/2.
Round to the nearest 10th a cylinder is 22 inches and 12.5 inches what is the surface area 
Answers
SA = 2π(11)^2 + 2π(11)(12.5)
SA = 2π(121) + 2π(137.5)
SA = 242π + 275π
SA = 517π
SA ≈ 1624.05 square inches
Rounding to the nearest tenth, the surface area of the cylinder is approximately 1624.1 square inches.
a bank took a sample of 100 of its delinquent credit card accounts and found that the mean owed on these accounts was $2,130. it is known that the standard deviation for all delinquent credit card accounts at this bank is $578. (hint: first write out the values for n, , and ) 1. what is the margin of error for the sample mean at a 95% confidence level? hint: look at the notes given above to see how the margin of error is computed. 2. will the margin of error increase/decrease if 200 delinquent credit cards were sampled instead of 100? why? hint: look at the notes given above to see how the margin of error is computed and how the sample size n impacts its value.
Answers
Sampled 200 delinquent credit card accounts instead of 100, the margin of error would decrease.
Sampled 200 delinquent credit card accounts, the margin of error for the sample mean at a 95% confidence level would be $80.164.
Smaller than the margin of error we found earlier for a sample size of 100.
The margin of error for the sample means at a 95% confidence level, we need to use the formula:
[tex]Margin of error = z\times (standard deviation / square root of sample size)[/tex]
[tex]z\times[/tex] is the z-score for the 95% confidence level, which is 1.96.
So, plugging in the given values, we get:
[tex]Margin of error = 1.96 \times (578 / \sqrt 100)[/tex]
[tex]Margin of error = 1.96 \times 57.8[/tex]
Margin of error = 113.008
Therefore, the margin of error for the sample mean at a 95% confidence level is $113.008.
Repeated samples of 100 delinquent credit card accounts and computed the sample mean each time, we would expect the true population mean to be within $113.008 of our sample mean about 95% of the time.
The margin of error is inversely proportional to the square root of the sample size. So, as the sample size increases, the margin of error decreases.
To see this, let's plug in the new sample size into the margin of error formula:
[tex]Margin of error = 1.96 \times (578 / \sqrt 200)[/tex]
[tex]Margin of error = 1.96 \times 40.9[/tex]
Margin of error = 80.164
For similar questions on Margin
https://brainly.com/question/30404882
#SPJ11
A $2 coin with a diameter of 25. 75 mm. How many turns does such a piece make if you roll it on the edge for 1. 34 m?
Answers
The coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
How to find the number of turns the coin makes?The circumference of the coin can be calculated as follows to determine the number of turns it makes:
C = πd
where C is the circumference, d is the diameter, and π is the mathematical constant pi (approximately equal to 3.14159).
So, for the given $2 coin with a diameter of 25.75 mm, the circumference is:
C = πd = 3.14159 x 25.75 mm ≈ 80.926 mm
Divide the distance traveled by the coin's circumference to determine the number of turns it makes when rolled on its edge for 1.34 meter:
Number of turns = distance traveled / circumference of the coin
Number of turns = 1.34 m / 0.080926 m
Number of turns ≈ 16.53
Therefore, the coin makes approximately 16.53 turns when rolled on its edge for 1.34 m.
know more about circumference visit :
https://brainly.com/question/28757341
#SPJ1
Devon invested $9500 in three different mutual funds. A fund containing large cap stocks made a 4.7% return in 1 yr. A real estate fund lost 12.2% in 1 yr, and a bond fund made 5.4% in 1 yr. The amount invested in the large cap stock fund was twice the amount invested in the real estate fund. If Devon had a net return of $133 across all investments, how much did he invest in each fund?
Answers
These investments do indeed produce a net return of $133.
What is algebra?
Algebra is a branch of mathematics that deals with mathematical operations and symbols used to represent numbers and quantities in equations and formulas.
Let's call the amount Devon invested in the real estate fund "x". Then, we know that the amount invested in the large cap stock fund is twice that, or "2x". The total amount invested is $9500, so we can write:
x + 2x + y = 9500
where "y" is the amount invested in the bond fund.
We also know the returns of each fund, so we can calculate the total return on the investments:
0.047(2x) - 0.122x + 0.054y = 133
Simplifying this equation, we get:
0.998x + 0.054y = 133
We have two equations and two unknowns (x and y), so we can solve for them. Let's start by solving the first equation for y:
y = 9500 - 3x
Now we can substitute this expression for y into the second equation:
0.998x + 0.054(9500 - 3x) = 133
Simplifying and solving for x, we get:
0.888x = 459.8
x = 517.57
So Devon invested $517.57 in the real estate fund. The amount invested in the large cap stock fund is twice that, or $1035.14. The amount invested in the bond fund is:
y = 9500 - 3x = 8464.29
To check that these investments produce a net return of $133, we can calculate the total return on each investment and add them up:
0.047(2x) - 0.122x + 0.054y = 0.047(2517.57) - 0.122517.57 + 0.054*8464.29 = 133.00
So these investments do indeed produce a net return of $133.
To learn more about algebra from the given link:
https://brainly.com/question/24875240
#SPJ1
What is the difference of the fractions? 4/7 - 10/7
Answers
Answer:
-6/7
Step-by-step explanation:
If s(d) represents the number of songs downloaded in a year d, what is the interpretation of s(2020) = 5,220,000.
A. 5,220,000 songs were downloaded in the year 2020.
B. There is not enough information to interpret the information.
C. In the year 2020 $5,220,000 was earned from downloaded songs.
D. 2,020 songs were downloaded at a cost of $5,220,000.
Answers
Answer: A. 5,220,000 songs were downloaded in the year 2020.
Step-by-step explanation: The interpretation of s(2020) = 5,220,000 is that in the year 2020, 5,220,000 songs were downloaded. The function s(d) represents the number of songs downloaded in a year d, so plugging in 2020 for d gives us the specific number of songs downloaded in that year.
we randomly select 100 pell grant recipients from two states. state a is a relatively small state with approximately 4,000 pell grant recipients. state b is a large state with approximately 200,000 pell grant recipients. suppose that the mean and standard deviation in individual pell grants is approximately the same for both states: and . for which state is the sample mean for our 100 pell grant recipients most likely to be within $80 of $2,600?
Answers
The sample mean for 100 pell grant recipients is more likely to be within $80 of $2,600 for State A, given the relatively smaller population size and the use of the t-distribution.
To compare the two states, we need to calculate the probability of the sample mean for 100 pell grant recipients being within $80 of $2,600 for each state.
For State A, with only 4,000 pell grant recipients, the sample size of 100 is relatively large, but not enough to use the normal distribution. Therefore, we need to use the t-distribution, which has fatter tails than the normal distribution, making it more likely to produce extreme values. This means that the probability of the sample mean for 100 pell grant recipients being within $80 of $2,600 is higher for State A than for State B.
For State B, with a larger population of 200,000 pell grant recipients, the sample size of 100 is a small fraction of the population, allowing us to use the normal distribution. However, as the distribution is narrower than the t-distribution, the probability of the sample mean for 100 pell grant recipients being within $80 of $2,600 is lower for State B than for State A.
You can learn more about sample mean at: brainly.com/question/14127076
#SPJ11
Evaluate the expression when x = 7 (4x + 9) - 4(x - 1) + x
Answers
Answer:x= -67 over 24
Step-by-step explanation:
You are deciding between two cars with different engines and want the bigger
of the two. One engine displaces 350 cubic inches. The other displaces 5,500
cubic centimeters. Check all of the reasonable approaches to solving this
question.
Answers
The bigger engine is larger than the smaller one by 235.4724 cubic centimeters.
How is the bigger engine larger than other?We know that 1 inch=2.54 centimeters
Then 1 cubic inches-(2.54)^3 cubic centimeters
We have that:
⇒ 1 cubic inches=(2.54)3 = 16.3870 cubic centimeters
⇒350 cubic inches= 350 x 16.3870 = 5735.4724 cubic centimeters
Since, the other displaces 5,500 cubic centimeters and 5735.4724< 5500. The difference between them is:
= 5735.4724 - 5500
= 235.4724
Hence, the bigger engine larger than the smaller one by 235.4724 cubic centimeters.
Read more about Engine size
brainly.com/question/14439953
#SPJ1
Himpunan penyelesaian dari :
18 - 2x < 3.(2x - 1) - 3
adalah ….
Answers
Step-by-step explanation:
18-2x<3(2x-1)-3
21-2x<6x-3
24<8x
3<x
Interval notation
(3, ∞)
consider these functions f(x)=3x^3+8x-2 k(x)=4x what is the value of k(f(x)
Answers
The value of function k(f(x)) is 12x³ + 32x - 8.
What is Function composition:Function composition is a way to combine two or more functions to form a new function. In this case, we are given two functions f(x) and k(x), and we need to find the value of k(f(x)), which means we need to apply the function k(x) to the output of the function f(x).
Here we have
Functions f(x)= 3x³ +8x -2 and k(x) = 4x
To find k(f(x)), we need to substitute the expression for f(x) into k(x) wherever we see x. So, we have:
k(f(x)) = 4(f(x)) = 4(3x³ + 8x - 2)
We can simplify this expression by distributing the 4:
k(f(x)) = 12x³ + 32x - 8
Therefore,
The value of function k(f(x)) is 12x³ + 32x - 8.
Learn more about Functions at
https://brainly.com/question/23972305
#SPJ1
how many non-empty subsets s of {1, 2, 3, . . . , 8} are there such that the product of the elements of s is at most 200?
Answers
The total number of non-empty subsets s of[tex]{1, 2, 3, . . . , 8}[/tex] such that the product of the elements of s is at most 200 is:
[tex]255 - (127 + 63 + 31) + 2 = 36.[/tex]
So, there are 36 such subsets.
Number of non-empty subsets s of[tex]{1, 2, 3, . . . , 8}[/tex] such that the product of the elements of s is at most 200, we can use a method called inclusion-exclusion principle.
First, we need to count the total number of non-empty subsets of the given set.
Since each element can either be included or excluded, there are [tex]2^8 - 1 = 255[/tex] non-empty subsets.
Next, we need to count the number of subsets whose product is greater than 200.
We can start by considering the subsets that contain 8, since 8 is the largest element in the set.
There are only two such subsets: {8} and {1, 8}.
Both of these subsets have a product greater than 200. Similarly, we can consider subsets that contain 7, and so on. We find that there are[tex]2^7 - 1 = 127[/tex] subsets that contain 7, and each of these subsets has a product greater than 200. Similarly, there are [tex]2^6 - 1 = 63[/tex] subsets that contain 6, and each of these subsets has a product greater than 200.
Double-counted the subsets that contain both 6 and 7, as well as those that contain both 6 and 8, and those that contain both 7 and 8.
Subtract the number of subsets that contain both 6 and 7, both 6 and 8, and both 7 and 8.
There are [tex]2^5 - 1 = 31[/tex] subsets that contain both 6 and 7, and each of these subsets has a product greater than 200.
Similarly, there are[tex]2^5 - 1 = 31[/tex] subsets that contain both 6 and 8, and each of these subsets has a product greater than 200.
Finally, there are [tex]2^5 - 1 = 31[/tex] subsets that contain both 7 and 8, and each of these subsets has a product greater than 200.
However, we have subtracted too much, since we have now excluded subsets that contain all three of 6, 7, and 8. There are only two such subsets: {6, 7, 8} and {1, 6, 7, 8}. Both of these subsets have a product greater than 200.
For similar questions on subsets
https://brainly.com/question/28705656
#SPJ11
To find the number of non-empty subsets s of {1, 2, 3, . . . , 8} such that the product of the elements of s is at most 200, we can use the concept of power set and combinatorics. By analyzing the pattern, we can determine that there are a total of 120 subsets whose product is at most 200.
Explanation:To find the number of non-empty subsets s of the set {1, 2, 3, . . . , 8} such that the product of the elements of s is at most 200, we can use the concept of power set and combinatorics. The power set of a set is the set of all its subsets. We know that the number of elements in the power set of a set with n elements is 2n. In this case, we have 8 elements in the set, so the power set will have 28 = 256 subsets. However, we need to find the number of subsets with a product at most 200.
We can analyze the products of all subsets to determine the count.
By analyzing the pattern, we can determine that there are a total of 120 subsets whose product is at most 200. This can be calculated by summing the total number of subsets for each number of elements (1-element subsets + 2-element subsets + 3-element subsets + ... + 8-element subsets).
https://brainly.com/question/33319261
#SPJ12
Dylan bought 3 identical shirts online for a total cost of $71.83 including a flat rate of $7.99 for shipping. Complete an equation to find the cost of each shirt, s, using the numbers below.
Answers
Answer:
$21.28
Step-by-step explanation:
We Know
Dylan bought 3 identical shirts online for a total cost of $71.83
$7.99 for shipping
We have the equation:
71.83 = 3s + 7.99
63.84 = 3s
s = $21.28
So, each shirt cost $21.28
Choose is the following are either; likely, unlikely, impossible, certain, or as likely as not:
A. choosing the letter M from a bag that contains magnets for each letter in the alphabet.
B. choosing a consonant from a bag that contains magnets for each letter in the alphabet.
C. Drawing a red card from a deck of cards. ( I'm guessing the cards are number cards)
D. drawing a number between 2 and 20 from a deck of cards.
E. drawing the number 1 from a deck of cards
Answers
As likely as not (assuming the bag contains an equal number of magnets for each letter in the alphabet).
What is Probability?Probability is a measure of the likelihood or chance that a particular event will occur. It is expressed as a number between 0 and 1, with 0 indicating that the event is impossible and 1 indicating that the event is certain to occur.
In probability theory, the probability of an event is calculated by dividing the number of ways that the event can occur by the total number of possible outcomes. This is known as the probability formula:
probability = Number of favorable outcomes / Total number of possible outcomes
Probability is used in a wide range of fields, including statistics, finance, physics, and engineering, to model and analyze uncertain situations and make predictions.
B. Likely (assuming the bag contains an equal number of magnets for each letter in the alphabet, and that there are more consonants than vowels in the alphabet).
C. Unlikely (assuming the deck contains an equal number of red and black cards).
D. Impossible (assuming the deck contains only standard playing cards with 52 cards, including 13 cards for each of the four suits).
E. Unlikely (assuming the deck contains only standard playing cards with 52 cards, including 4 cards for each number or face value).
To learn more about probability, visit
https://brainly.com/question/30034780
#SPJ1